最近好久没发文章了,猫在家里研究宏观经济数据怎样预测股市走势。经过反复研究,终于有一个不错的结果。赶紧拿出来分享给小伙伴。讲真,看到结果的时候我是震惊的,只用了宏观数据,没有使用任何其他复合策略,结果竟能有这么高的准确率。
本文的策略可以用于宏观择时,配合行业分析和个股分析,定能有不错的结果。
本文代码大概600行左右,尽量呈现完整简练的策略开发代码框架,另有中间的数据分析和可视化部分删掉了,在其他类似策略研究时只要改一下数据和参数代码就可以直接使用,省时高效。
以下为策略介绍:
量化分析工作从大的方面可以分三部分:宏观、中观和微观。
宏观:通过研究宏观经济数据来分析、判断未来经济走势。
中观:依据行业数据,对行业趋势、轮动等进行分析。
微观:依据公司基本面数据,进行选股。
经济走势很大程度上会反应到股市当中,经济形式向好则股市为牛市的概率大。当经济基本面较弱,下行压力大,则股市冷淡。例如,2018年整体经济下行,股市下跌幅度较大,股市走势和宏观经济走势呈现强相关。在投资决策时,宏观经济预测将是最为重要的参考,在此基础上再做行业和企业层面的分析。
本文选用沪深300为标的,用以衡量大盘走势,依据宏观数据分析,预测未来走势。
采用的预测方法:经过机器学习算法和神经网络算法尝试,最后发现LSTM算法预测效果最好。
训练数据:采用2005年到2016年共11年数据作为训练数据。
预测范围:2016年至2019年,共3年。
预测周期:3个月,即用当前宏观数据预测未来3个月大盘走势。
LSTM数据周期:5,即用过去5期的数据作为输入数据。也就是说,认为过去5个月的宏观数据对未来预测有影响。
预测结果:
上图为基于预测结果进行买卖决策的收益,下图为沪深300走势图,从两图的对比中可以明显看出,在上升趋势时基本做了买入决定,在下降趋势时选择空仓。时机把握非常准确,回撤很小,曲线基本是一路上升。
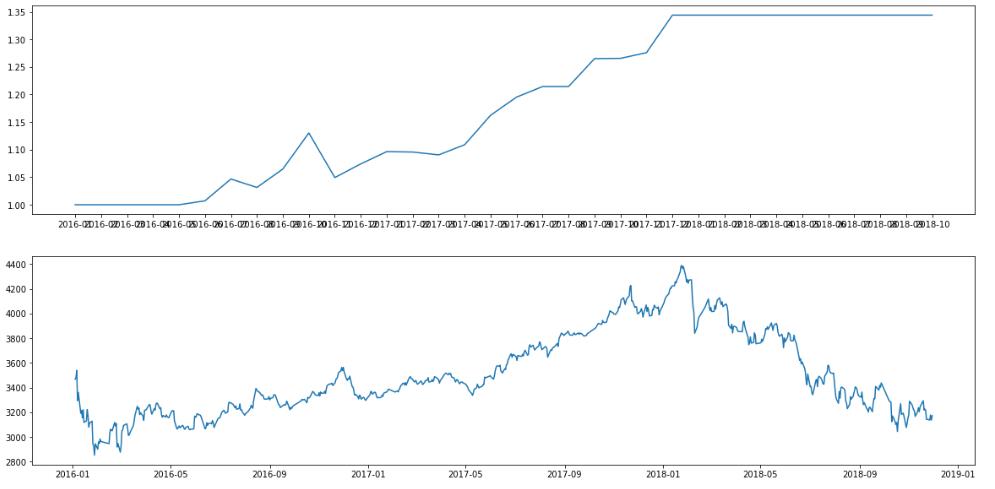
预测数据: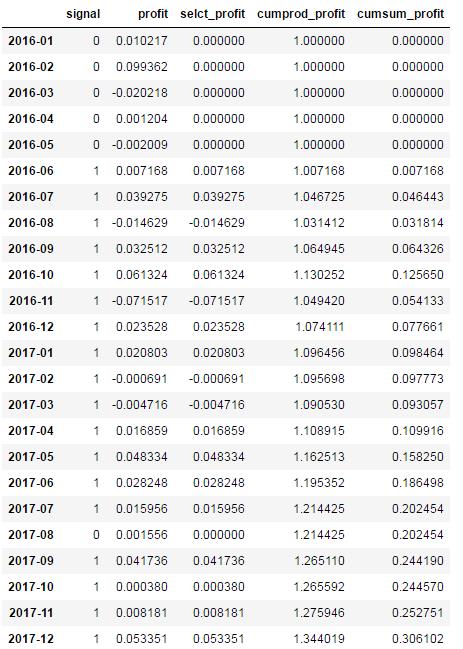

在对预测结果分析时发现,如果有做空机制,策略收益会更高,因为在下跌预测中也有不错的效果。A股正在慢慢放开做空,以后将会有正反两个盈利方向,策略效率翻倍。
不足之处:
本文代码使用数据量较大,算法耗时时间长,我的结果是在自己机器上跑的,在云端跑数据耗时太久,我就不跑了,大家可以复制代码到自己机器上跑,如果有问题欢迎交流。
由于聚宽云端策略模块尚不支持tensorflow和lightGBM等库,所以没法写成策略,只能以研究的方式分享,聚宽现在有客户端了,可以自己安装各种库,很好用,我在客户端写成策略,效果基本一致。
本策略只考虑了一个因素,不可能解释股市的复杂,需要结合其他策略配合使用。
import pandas as pd
import numpy as np
import datetime
from sklearn.svm import SVC,LinearSVC
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
import lightgbm as lgb
from sklearn.model_selection import train_test_split,GridSearchCV
import tensorflow as tf
import warnings
warnings.filterwarnings('ignore')
from sklearn.metrics import accuracy_score,recall_score
from sklearn.feature_selection import SelectKBest,SelectPercentile,SelectFromModel,chi2,f_classif,mutual_info_classif,RFE
from scipy.stats import pearsonr
from sklearn.ensemble import RandomForestRegressor,RandomForestClassifier
from sklearn.svm import SVC,LinearSVC,LinearSVR,SVR
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import gc
import pickle
import matplotlib.pyplot as plt
import time
from jqdata import *
start_date = '2005-01-01'
end_date = '2015-12-31'
test_start_date = '2016-01-01'
test_end_date = '2018-11-30'
start_year = start_date[:4]
end_year = end_date[:4]
select_index = '000300.XSHG'
n = 3 #data_y延期n月
stat_quarter = '2015-03'
stat_month = '2015-02'
seq_len = 5 #lstm back num
def get_year_list(start_year,end_year):
sy = int(start_year)
ey = int(end_year)
l = []
for i in range(sy,ey+1):
l.append(str(i))
return l
def get_quarter_list(start_year,end_year):
sy = int(start_year)
ey = int(end_year)
l = []
for y in range(sy,ey+1):
for q in range(3,13,3):
if q < 10:
s = str(y) + '-' + '0' + str(q)
l.append(s)
else:
s = str(y) + '-' + str(q)
l.append(s)
return l
def get_month_list(start_date,end_date):
sy = int(start_date[:4])
ey = int(end_date[:4])
sm = int(start_date[5:7])
em = int(end_date[5:7])
l = []
for y in range(sy,ey+1):
if y == sy:
for i in range(sm,13):
if i< 10:
s = str(y) + '-' + '0' + str(i)
l.append(s)
else:
s = str(y) + '-' + str(i)
l.append(s)
elif y == ey:
for i in range(1,em+1):
if i < 10:
s = str(y) + '-' + '0' + str(i)
l.append(s)
else:
s = str(y) + '-' + str(i)
l.append(s)
else:
for i in range(1,13):
if i < 10:
s = str(y) + '-' + '0' + str(i)
l.append(s)
else:
s = str(y) + '-' + str(i)
l.append(s)
return l
##获取宏观数据
def get_macro_data(month_list,start_date,end_date):
#社会消费品销售总额
sr = macro.MAC_SALE_RETAIL_MONTH
q = query(sr.stat_month,sr.retail_sin,sr.retail_sin_yoy,sr.retail_acc_yoy)\
.filter(macro.MAC_SALE_RETAIL_MONTH.stat_month.in_(month_list))\
.order_by(macro.MAC_SALE_RETAIL_MONTH.stat_month)
sale = macro.run_query(q).dropna(axis=1,how='all').fillna(method='ffill')
q_a = query(sr).filter(macro.MAC_SALE_RETAIL_MONTH.stat_month.in_(month_list))\
.order_by(macro.MAC_SALE_RETAIL_MONTH.stat_month)
sale_a = macro.run_query(q_a).dropna(axis=1,how='all').fillna(method='ffill').fillna(method='bfill')
#房地产开发投资情况表
ie = macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH
q_estate = query(macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.stat_month,macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.invest,\
macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.invest_yoy)\
.filter(macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.stat_month.in_(month_list))\
.order_by(macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.stat_month)
estate = macro.run_query(q_estate)
q_estate_a = query(ie).filter(macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.stat_month.in_(month_list)).order_by(macro.MAC_INDUSTRY_ESTATE_INVEST_MONTH.stat_month)
estate_a = macro.run_query(q_estate_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#70个大中城市房屋销售价格指数(月度)
q_70city_eatate = query(macro.MAC_INDUSTRY_ESTATE_70CITY_INDEX_MONTH.stat_month,macro.MAC_INDUSTRY_ESTATE_70CITY_INDEX_MONTH.commodity_house_idx)\
.filter(macro.MAC_INDUSTRY_ESTATE_70CITY_INDEX_MONTH.stat_month.in_(month_list)).order_by(macro.MAC_INDUSTRY_ESTATE_70CITY_INDEX_MONTH.stat_month)
city_eatate_all = macro.run_query(q_70city_eatate).fillna(method='ffill')
city_eatate = city_eatate_all.groupby(['stat_month']).mean()
#黄金和外汇储备
#数据从2008年开始
gf = macro.MAC_GOLD_FOREIGN_RESERVE
q_gold_foreign = query(gf.stat_date,gf.gold,gf.foreign).filter(gf.stat_date.in_(month_list)).order_by(gf.stat_date)
gold_foreign_0 = macro.run_query(q_gold_foreign)
gold_foreign_0['stat_month'] = gold_foreign_0['stat_date']
gold_foreign = gold_foreign_0.drop(['stat_date'],axis=1)
q_gold_foreign_a = query(gf).filter(gf.stat_date.in_(month_list)).order_by(gf.stat_date)
gold_foreign_1 = macro.run_query(q_gold_foreign_a)
gold_foreign_1['stat_month'] = gold_foreign_1['stat_date']
gold_foreign_a = gold_foreign_1.drop(['stat_date'],axis=1).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#固定资产投资
fi = macro.MAC_FIXED_INVESTMENT
q_fixed_inv = query(fi.stat_month,fi.fixed_assets_investment_yoy,fi.primary_yoy,fi.secondary_yoy,fi.tertiary_yoy,fi.centre_project_yoy)\
.filter(fi.stat_month.in_(month_list)).order_by(fi.stat_month)
fixed_inv = macro.run_query(q_fixed_inv).fillna(method='ffill')
q_fixed_inv_a = query(fi).filter(fi.stat_month.in_(month_list)).order_by(fi.stat_month)
fixed_inv_a = macro.run_query(q_fixed_inv_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#利用外资情况表
fc = macro.MAC_FOREIGN_CAPITAL_MONTH
q_foreign_cap = query(fc.stat_month,fc.num_acc_yoy).filter(fc.stat_month.in_(month_list)).order_by(fc.stat_month)
foreign_cap = macro.run_query(q_foreign_cap).fillna(method='ffill')
q_foreign_cap_a = query(fc).filter(fc.stat_month.in_(month_list)).order_by(fc.stat_month)
foreign_cap_a = macro.run_query(q_foreign_cap_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#宏观经济景气指数
eb = macro.MAC_ECONOMIC_BOOM_IDX
q_eco_boom = query(eb.stat_month,eb.early_warning_idx,eb.consistency_idx,eb.early_warning_idx,eb.lagging_idx)\
.filter(eb.stat_month.in_(month_list)).order_by(eb.stat_month)
economic_boom = macro.run_query(q_eco_boom)
q_eco_boom_a = query(eb).filter(eb.stat_month.in_(month_list)).order_by(eb.stat_month)
economic_boom_a = macro.run_query(q_eco_boom_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#制造业采购经理指数(PMI)
mf = macro.MAC_MANUFACTURING_PMI
q_pmi = query(mf.stat_month,mf.pmi).filter(mf.stat_month.in_(month_list)).order_by(mf.stat_month)
pmi = macro.run_query(q_pmi)
pmi_m = pmi['pmi'] - 50 #该指数以50为中心,大于表示制造业扩张,反之表示衰退
pmi['pmi'] = pmi_m
q_pmi_a = query(mf).filter(mf.stat_month.in_(month_list)).order_by(mf.stat_month)
pmi_a = macro.run_query(q_pmi_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#全国工业增长速度
ig = macro.MAC_INDUSTRY_GROWTH
q_industry_growth = query(ig.stat_month,ig.growth_yoy,ig.growth_acc).filter(ig.stat_month.in_(month_list)).order_by(ig.stat_month)
industry_growth = macro.run_query(q_industry_growth).fillna(method='ffill')
industry_growth_diff = industry_growth['growth_acc'].diff().fillna(0)
industry_growth['growth_acc_diff'] = industry_growth_diff
q_industry_growth_a = query(ig).filter(ig.stat_month.in_(month_list)).order_by(ig.stat_month)
industry_growth_a = macro.run_query(q_industry_growth_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#全国工业企业主要经济指标
ii = macro.MAC_INDUSTRY_INDICATOR
q_industry_indicator = query(ii.stat_month,ii.enterprise_value_acc,ii.loss_enterprise_ratio_acc,\
ii.total_interest_ratio_acc).filter(ii.stat_month.in_(month_list)).order_by(ii.stat_month)
industry_indicator = macro.run_query(q_industry_indicator)
industry_indicator_diff = industry_indicator['enterprise_value_acc'].diff().fillna(method='bfill')
industry_indicator['enterprise_value_acc_diff'] = industry_indicator_diff/industry_indicator['enterprise_value_acc'].shift().fillna(method='bfill')
industry_indicator['loss_enterprise_ratio_acc_diff'] = industry_indicator['loss_enterprise_ratio_acc'].diff()
industry_indicator['total_interest_ratio_acc_diff'] = industry_indicator['total_interest_ratio_acc'].diff()
industry_indicator = industry_indicator.fillna(method='bfill')
l = ['stat_month','enterprise_value_acc_diff','loss_enterprise_ratio_acc_diff','total_interest_ratio_acc_diff']
industry_indicator = industry_indicator[l]
q_industry_indicator_a = query(ii).filter(ii.stat_month.in_(month_list)).order_by(ii.stat_month)
industry_indicator_a = macro.run_query(q_industry_indicator_a).dropna(how='all',axis=1).fillna(method='ffill').fillna(method='bfill')
#月度宏观经济指标
month_macro_indicators = [sale,estate,fixed_inv,foreign_cap,economic_boom,pmi,industry_growth,industry_indicator]
mg = sale['stat_month'].to_frame()
for ind in month_macro_indicators:
mg = pd.merge(mg,ind,left_on=['stat_month'],right_on=['stat_month'],how='left')
res = mg.fillna(method='ffill').fillna(method='bfill')
month_macro_indicators_a = [sale_a,estate_a,fixed_inv_a,foreign_cap_a,economic_boom_a,\
pmi_a,industry_growth_a,industry_indicator_a]
for ind in month_macro_indicators_a:
mg_a = pd.merge(mg,ind,left_on=['stat_month'],right_on=['stat_month'],how='left')
res_a = mg_a.fillna(method='ffill').fillna(method='bfill')
price = get_price(select_index,start_date=start_date,end_date=end_date,fields=['close'])
data = [res,res_a,price]
return data
#获取月度价格数据
def get_price_month_data(price,n='mean',mean_num=1):
'''
:param price: 输入价格数据,index为datetime类型
:param type: 计算方式,’mean‘取月平均值,若为int,则从第几个交易日开始计算均值,长度为mean_num,
:param mean_num: 计算均值的长度
:return:
'''
ind = list(price.index)
s_ind = [datetime.datetime.strftime(i, '%Y%m%d') for i in ind]
price.index = s_ind
num_ind = [int(i) for i in s_ind]
cut_ind = [int(i / 100) for i in num_ind]
cut_s_ind = [(str(i)[:4] + '-' + str(i)[4:]) for i in cut_ind]
price['stat_date'] = cut_s_ind
if n == 'mean':
res = price.groupby(by=['stat_date']).mean()
else:
ind_sig = list(set(price['stat_date'].values))
index_list = []
mean_list = []
for ind in ind_sig:
df = price[price['stat_date']==ind]
sel_df = df.iloc[n-1:n+mean_num-1,0]
index = list(sel_df.index)
if len(index) == 0:
continue
index = index[0]
index_list.append(index)
mean_df = sel_df.mean()
mean_list.append(mean_df)
res_df = pd.DataFrame(mean_list,index=index_list,columns=['month_price'])
res = res_df.sort_index()
res_index = list(res.index)
ind_s_cut = [i[:4] + '-' + i[4:6] for i in res_index]
res.index = ind_s_cut
return res
def get_pure_values(data):
'''
获取纯净数值,将DataFrame中的非数值项剔除,例如‘code’项(str)
input:
data:pd.DataFrame,index为股票代码
putput:
DataFrame:只含数值项
'''
columns = list(data.columns)
for column in columns:
if not(isinstance(data[column][0],int) or isinstance(data[column][0],float)):
data = data.drop([column],axis=1)
return data
def winsorize_and_standarlize(data, qrange=[0.05, 0.95], axis=0):
if isinstance(data, pd.DataFrame):
if axis == 0:
q_down = data.quantile(qrange[0])
q_up = data.quantile(qrange[1])
col = data.columns
for n in col:
data[n][data[n] > q_up[n]] = q_up[n]
data[n][data[n] < q_down[n]] = q_down[n]
data = (data - data.mean()) / data.std()
data = data.fillna(0)
else:
data = data.stack()
data = data.unstack(0)
q_down = data.quantile(qrange[0])
q_up = data.quantile(qrange[1])
col = data.columns
for n in col:
data[n][data[n] > q_up[n]] = q_up[n]
data[n][data[n] < q_down[n]] = q_down[n]
data = (data - data.mean()) / data.std()
data = data.stack().unstack(0)
data = data.fillna(0)
elif isinstance(data, pd.Series):
q_down = data.quantile(qrange[0])
q_up = data.quantile(qrange[1])
data[data > q_up] = q_up
data[data < q_down] = q_down
data = (data - data.mean()) / data.std()
return data
def get_profit_class(data):
'''
对数据进行分类标记
'''
data_diff = data.diff(n)
data_diff[data_diff > 0] = 1
data_diff[data_diff < 0] = 0
#data_diff[data_diff == 2] = -1
#data_diff[data_diff == -2] = 1
return data_diff
def get_final_data(input_x,input_y):
input_y = input_y.shift(-n).to_frame().fillna(method='ffill')
data_m = pd.merge(input_x,input_y,left_index=True,right_index=True,how='right')
columns_m = data_m.columns
data_x = data_m[columns_m[:-1]]
data_y = data_m[columns_m[-1]]
return data_x,data_y
class FeatureSelection():
'''
特征选择:
identify_collinear:基于相关系数,删除小于correlation_threshold的特征
identify_importance_lgbm:基于LightGBM算法,得到feature_importance,选择和大于p_importance的特征
filter_select:单变量选择,指定k,selectKBest基于method提供的算法选择前k个特征,selectPercentile选择前p百分百的特征
wrapper_select:RFE,基于estimator递归特征消除,保留n_feature_to_select个特征
'''
def __init__(self):
self.filter_supports = None #bool型,特征是否被选中
self.wrapper_supports = None
self.embedded_supports = None
self.lgbm_columns = None #选择的特征
self.filter_columns = None
self.wrapper_columns = None
self.embedded_columns = None
self.record_collinear = None #自相关矩阵大于门限值
def identify_collinear(self, data, correlation_threshold):
columns = data.columns
self.correlation_threshold = correlation_threshold
# Calculate the correlations between every column
corr_matrix = data.corr()
self.corr_matrix = corr_matrix
# Extract the upper triangle of the correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k = 1).astype(np.bool))
# Select the features with correlations above the threshold
# Need to use the absolute value
to_drop = [column for column in upper.columns if any(upper[column].abs() > correlation_threshold)]
obtain_columns = [column for column in columns if column not in to_drop]
self.columns = obtain_columns
# Dataframe to hold correlated pairs
record_collinear = pd.DataFrame(columns = ['drop_feature', 'corr_feature', 'corr_value'])
# Iterate through the columns to drop
for column in to_drop:
# Find the correlated features
corr_features = list(upper.index[upper[column].abs() > correlation_threshold])
# Find the correlated values
corr_values = list(upper[column][upper[column].abs() > correlation_threshold])
drop_features = [column for _ in range(len(corr_features))]
# Record the information (need a temp df for now)
temp_df = pd.DataFrame.from_dict({'drop_feature': drop_features,
'corr_feature': corr_features,
'corr_value': corr_values})
# Add to dataframe
record_collinear = record_collinear.append(temp_df, ignore_index = True)
self.record_collinear = record_collinear
return data[obtain_columns]
def identify_importance_lgbm(self, features, labels,p_importance=0.8, eval_metric='auc', task='classification',
n_iterations=10, early_stopping = True):
# One hot encoding
data = features
features = pd.get_dummies(features)
# Extract feature names
feature_names = list(features.columns)
# Convert to np array
features = np.array(features)
labels = np.array(labels).reshape((-1, ))
# Empty array for feature importances
feature_importance_values = np.zeros(len(feature_names))
#print('Training Gradient Boosting Model\n')
# Iterate through each fold
for _ in range(n_iterations):
if task == 'classification':
model = lgb.LGBMClassifier(n_estimators=100, learning_rate = 0.05, verbose = -1)
elif task == 'regression':
model = lgb.LGBMRegressor(n_estimators=100, learning_rate = 0.05, verbose = -1)
else:
raise ValueError('Task must be either "classification" or "regression"')
# If training using early stopping need a validation set
if early_stopping:
train_features, valid_features, train_labels, valid_labels = train_test_split(features, labels, test_size = 0.15)
# Train the model with early stopping
model.fit(train_features, train_labels, eval_metric = eval_metric,
eval_set = [(valid_features, valid_labels)],
verbose = -1)
# Clean up memory
gc.enable()
del train_features, train_labels, valid_features, valid_labels
gc.collect()
else:
model.fit(features, labels)
# Record the feature importances
feature_importance_values += model.feature_importances_ / n_iterations
feature_importances = pd.DataFrame({'feature': feature_names, 'importance': feature_importance_values})
# Sort features according to importance
feature_importances = feature_importances.sort_values('importance', ascending = False).reset_index(drop = True)
# Normalize the feature importances to add up to one
feature_importances['normalized_importance'] = feature_importances['importance'] / feature_importances['importance'].sum()
feature_importances['cumulative_importance'] = np.cumsum(feature_importances['normalized_importance'])
select_df = feature_importances[feature_importances['cumulative_importance']<=p_importance]
select_columns = select_df['feature']
self.lgbm_columns = list(select_columns.values)
res = data[self.columns]
return res
def filter_select(self, data_x, data_y, k=None, p=50,method=f_classif):
columns = data_x.columns
if k != None:
model = SelectKBest(method,k)
res = model.fit_transform(data_x,data_y)
supports = model.get_support()
else:
model = SelectPercentile(method,p)
res = model.fit_transform(data_x,data_y)
supports = model.get_support()
self.filter_support_ = supports
self.filter_columns = columns[supports]
return res
def wrapper_select(self,data_x,data_y,n,estimator):
columns = data_x.columns
model = RFE(estimator=estimator,n_features_to_select=n)
res = model.fit_transform(data_x,data_y)
supports = model.get_support() #标识被选择的特征在原数据中的位置
self.wrapper_supports = supports
self.wrapper_columns = columns[supports]
return res
def embedded_select(self,data_x,data_y,estimator,threshold=None):
columns = data_x.columns
model = SelectFromModel(estimator=estimator,prefit=False,threshold=threshold)
res = model.fit_transform(data_x,data_y)
supports = model.get_support()
self.embedded_supports = supports
self.embedded_columns = columns[supports]
return res
#调参时计算召回率和准确率
def lstm_recall(prediction,y,n=1,thr=0.5):
len_p = len(prediction)
l = 0
z = 0
res = []
if n == 1:
for i in range(len_p):
if (prediction[i]>= thr):
l = l+1
if (y[i] ==1):
z = z+1
elif n==0:
for i in range(len_p):
if (prediction[i]<=thr):
l = l+1
if (y[i] ==0):
z = z+1
lstm_recall = z/l
return lstm_recall
def lstm_accuracy(prediction,y,thr=0.5):
len_p = len(prediction)
l = 0
for i in range(len_p):
if ((prediction[i]>=thr) & (y[i] ==1)) | ((prediction[i]<thr) & (y[i] ==0)):
l = l + 1
accuracy = l/len_p
return accuracy
def res_output(res,buy_thr=1.6,sell_thr=0.5):
'''
基于lgbm和embedded两组特征选择数据的计算结果确定预测结果
buy_thr:预测股价上升的门限值,默认1.5,
sell_thr:预测股价下降的门限值,默认0.5
大于买入门限标记为1,小于卖出门限标记为-1,中间值认为买入卖出信号不强,选择观望或空仓,卖出信号可用于做空,在无法做空时认为空仓
'''
length = len(res)
l = []
for i in range(length):
if res[i] > buy_thr:
l.append(1)
elif res[i] < sell_thr:
l.append(-1)
else:
l.append(0)
return l
def LSTM_fun(n_input,train_x,train_y,predict_x,seq_len=5):
#LSTM
lr=0.1
lstm_size = 3 #lstm cell数量,基于数据量调整
epoch_num = 10 #打印次数,和n_batch相乘便是迭代次数
n_batch = 300
lookback = seq_len
tf.reset_default_graph()
x = tf.placeholder(tf.float32,[None,lookback,n_input])
y = tf.placeholder(tf.float32,[None,1])
weights = tf.Variable(tf.truncated_normal([lstm_size,1],stddev=0.1))
biases = tf.Variable(tf.constant(0.1,shape=[1]))
def LSTM_net(x,weights,biases):
lstm_cell = tf.contrib.rnn.LSTMCell(lstm_size,name='basic_lstm_cell') #.BasicLSTMCell(lstm_size)
output,final_state = tf.nn.dynamic_rnn(lstm_cell,x,dtype=tf.float32)
results = tf.nn.sigmoid(tf.matmul(final_state[1],weights)+biases)
return results
prediction = LSTM_net(x,weights,biases)
loss = tf.reduce_mean(tf.square(y - prediction))
train_step = tf.train.GradientDescentOptimizer(lr).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(epoch_num):
for j in range(n_batch):
sess.run(train_step,feed_dict={x:train_x,y:train_y})
#train_loss = sess.run(loss,feed_dict={x:train_x,y:train_y})
# print('train loss is'+ str(train_loss))
prediction_res = sess.run(prediction,feed_dict={x:predict_x})
return prediction_res
def get_test_time_list(start_date,test_start_date,test_end_date):
'''
使用机器学习算法计算时的时间数据
input:
start_date:取宏观数据的开始时间
test_start_date:预测的开始时间,也就是取宏观数据的截止时间
test_end_date:预测的截止时间,对期间的每一个月都要预测,每一个月都要重跑一遍预测函数,每个月的开始使用上个月28号的价格数据作为截止价格时间
output:
m_l:每一次预测时的月份列表,在此列表内跑预测函数,
start_date,取宏观数据和价格数据的开始时间,由全局变量定义
ed:取价格数据截止时间列表,顺序和m_l对应
'''
test_month = get_month_list(test_start_date,test_end_date)
m_l_pre = []
ed = []
for m in test_month:
ml = get_month_list(start_date,m)
m_l_pre.append(ml)
if m == test_month[-1]:
ed.append(test_end_date)
else:
ed.append(m+'-'+'28')
return m_l_pre,start_date,ed
ml,sd,ed = get_test_time_list(start_date,test_start_date,test_end_date)
def monthly_fun(month_list, start_date, end_date):
macro_data_o = get_macro_data(month_list,start_date, end_date)
res = macro_data_o[0]
res_a = macro_data_o[1]
price = macro_data_o[2]
price_month = get_price_month_data(price)
res.index = res['stat_month']
res_a.index = res['stat_month']
sel_data = pd.merge(res_a, price_month, left_index=True, right_index=True).dropna() # 使用全部宏观数据
data_pure = get_pure_values(sel_data)
columns = data_pure.columns
data_x_start = data_pure[columns[:-1]]
data_y_o = data_pure[columns[-1]]
data_x_o = winsorize_and_standarlize(data_x_start)
data_y_class_o = get_profit_class(data_y_o)
data_x, data_y_class = get_final_data(data_x_o, data_y_class_o)
_, data_y = get_final_data(data_x_o, data_y_o)
# 特征选择
f = FeatureSelection()
n_collinear = f.identify_collinear(data_x, correlation_threshold=0.8) #去除一些共线性特征
lgbm_res = f.identify_importance_lgbm(n_collinear, data_y_class, p_importance=0.9)
estimator = LinearSVC()
wrapper_res = f.wrapper_select(data_x=n_collinear, data_y=data_y_class, n=5, estimator=estimator)
est = LinearSVC(C=0.01, penalty='l1', dual=False)
est1 = RandomForestClassifier()
embedded_res = f.embedded_select(data_x=n_collinear, data_y=data_y_class, estimator=est1)
# LSTM数据准备
lgbm_n_input = len(lgbm_res.columns)
lgbm_x_a = np.array(lgbm_res)
lgbm_x_o = [lgbm_x_a[i: i + seq_len, :] for i in range(lgbm_res.shape[0] - seq_len)]
lgbm_x_l = len(lgbm_x_o)
lgbm_x_array = np.reshape(lgbm_x_o, [lgbm_x_l, seq_len, lgbm_n_input])
lgbm_x = lgbm_x_array[:-n]
lgbm_x_prediction = lgbm_x_array[-n:]
lgbm_y_o = np.array([data_y_class[i + seq_len] for i in range(len(data_y_class) - seq_len)])
lgbm_y_array = np.reshape(lgbm_y_o, [lgbm_y_o.shape[0], 1])
lgbm_y = lgbm_y_array[:-n]
lgbm_y_prediction = lgbm_y_array[-n:]
# print(len(lgbm_y))
embedded_n_input = np.shape(embedded_res)[1]
embedded_x_a = np.array(embedded_res)
embedded_x_o = [embedded_x_a[i: i + seq_len, :] for i in range(embedded_res.shape[0] - seq_len)]
embedded_x_l = len(embedded_x_o)
embedded_x_array = np.reshape(embedded_x_o, [embedded_x_l, seq_len, embedded_n_input])
embedded_x = embedded_x_array[:-n]
embedded_x_predition = embedded_x_array[-n:]
embedded_y_o = np.array([data_y_class[i + seq_len] for i in range(len(data_y_class) - seq_len)])
embedded_y_array = np.reshape(embedded_y_o, [embedded_y_o.shape[0], 1])
embedded_y = embedded_y_array[:-n]
# 获取训练数据和测试数据
# lgbm_train_x,lgbm_test_x,lgbm_train_y,lgbm_test_y = train_test_split(lgbm_x,lgbm_y,test_size=0.3,random_state=0)
# embedded_train_x,embedded_test_x,embedded_train_y,embedded_test_y = train_test_split(embedded_x,embedded_y,test_size=0.3,random_state=0)
lgbm_pre_res = LSTM_fun(lgbm_n_input, lgbm_x, lgbm_y, lgbm_x_prediction, seq_len=seq_len)
embedded_pre_res = LSTM_fun(embedded_n_input, embedded_x, embedded_y, embedded_x_predition, seq_len=seq_len)
# print(lgbm_pre_res)
# print(embedded_pre_res)
pre_res = lgbm_pre_res + embedded_pre_res # 将两组数据的的预测结果相加
signal = res_output(pre_res)
# print(signal)
return signal
def get_pre_signal(ml,sd,ed):
'''
在时间序列下计算最后三个月的预测值,以此作为决策信号
'''
start_clock = time.clock()
length = len(ml)
l = []
for i in range(length):
month_l = ml[i]
end_d = ed[i]
pre = monthly_fun(month_l,sd,end_d)
l.append(pre)
end_clock = time.clock()
clofk_diff = (end_clock - start_clock)/60
print('time cost:%0.3f'%clofk_diff)
return l
pre_res_l = get_pre_signal(ml,sd,ed)
#只适应与n=3的情况
def get_buy_sell_signal(pre_res):
'''
由于预测的是未来三个月(n=3)的的情况,预测有重合部分,将重合部分取平均,基于均值做买卖决策,提高精度
此函数只适应与n=3的情况
'''
length = len(pre_res)
l = []
for i in range(length):
if i == 0:
l.append(pre_res[0][0])
elif i == 1:
s = (pre_res[0][1]+pre_res[1][0])/2
l.append(s)
elif i == length-1:
l.append((pre_res[i][0]+pre_res[i-1][1]+pre_res[i-2][2])/3)
l.append((pre_res[i][1]+pre_res[i-1][2])/2)
l.append(pre_res[i][2])
else:
t = (pre_res[i][0]+pre_res[i-1][1]+pre_res[i-2][2])/3
l.append(t)
return l
bs_signal = get_buy_sell_signal(pre_res_l)
def get_buy_month_list(signal,test_start_date,test_end_date):
test_month = get_month_list(test_start_date,test_end_date)
length = len(signal)
dic = {}
for i in range(n,length+1):
l = []
for j in range(n):
l.append(signal[i-(n-j)])
dic[test_month[i-n]] = l
return dic
dic = get_buy_month_list(bs_signal,test_start_date,test_end_date)
def get_month_buy_signal(dic,test_start_date,test_end_date):
'''
获取每月买卖信号,卖出信号为[0,0,0]、[1,0,0]、[1,1,0],其余为卖出信号,001、010、011、101、111为买入信号,信号分析没有考虑做空
input:
dic: dic,key为月份,value为对应的信号
'''
test_month = get_month_list(test_start_date,test_end_date)
dic_month_signal = {}
for m in test_month:
l = dic[m]
if (l[0]<0.5) & (l[1]<0.5) & (l[2]<0.5):
dic_month_signal[m] = 0
elif (l[0]>0.5) & (l[1]<0.5) & (l[2]<0.5):
dic_month_signal[m] = 0
elif (l[0]>0.5) & (l[1]>0.5) & (l[2]<0.5):
dic_month_signal[m] = 0
else:
dic_month_signal[m] = 1
v = list(dic_month_signal.values())
df = pd.DataFrame(v,index=dic_month_signal.keys(),columns=['signal'])
return df
month_signal = get_month_buy_signal(dic,test_start_date,test_end_date)
def get_month_profit(stocks,start_date,end_date):
'''
获取月收益率数据,数据为本月相对于上月的增长率,计算时用每月最后MONTH_MEAN_DAY_NUM天的均值
input:
data:dataframe,index为股票代码,values为因子值
start_date:str, 初始日期
end_date:str,终止日期
output:
month_profit_df: Dataframe,columns为每月第一天的收盘价
'''
start_year = int(start_date[:4])
end_year = int(end_date[:4])
start_month = int(start_date[5:7])
end_month = int(end_date[5:7])
len_month = (end_year - start_year)*12 + (end_month - start_month) + 2
price_list = []
for i in range(len_month):
date = str(start_year+i//12)+'-'+str(start_month+i%12)+'-'+'01'
price = get_price(stocks,fields=['close'],count=1,end_date=date)['close']
price_list.append(price)
month_profit = pd.concat(price_list,axis=0)
v = list(month_profit.values)
month_profit_df = pd.DataFrame(v,index=month_profit.index,columns=['profit'])
return month_profit_df
month_profit = get_month_profit(select_index,test_start_date,test_end_date)
month_profit_pct = month_profit.pct_change(1,axis=0).dropna(how='all')
def get_strategy_profit(month_signal,month_profit_pct):
length_signal = len(month_signal)
length_pct = len(month_profit_pct)
if length_signal != length_pct:
print('input references must have same length')
month_profit_pct_shift = month_profit_pct['profit'].shift(-1)
month_signal['profit'] = month_profit_pct_shift.values
month_signal = month_signal.dropna()
month_signal['profit'][month_signal['signal']==0] = 0
month_signal['selct_profit'] = month_signal['profit']
month_signal['cumprod_profit'] = (month_signal['selct_profit']+1).cumprod()
month_signal['cumsum_profit'] = month_signal['selct_profit'].cumsum()
return month_signal
strategy_profit = get_strategy_profit(month_signal,month_profit_pct)
sp_cumprod = strategy_profit['cumprod_profit']
p_hs300 = get_price(select_index,start_date=test_start_date,end_date=test_end_date,fields=['close'])
fig = plt.figure(figsize=(20,10))
ax0 = fig.add_subplot(2,1,1)
ax1 = fig.add_subplot(2,1,2)
ax0.plot(sp_cumprod)
ax1.plot(p_hs300)
plt.show()