最好的学习方法是教会他人
本文目录:
一、亚马逊商品页面爬取
二、百度/360搜索关键字提交
三、网络图片的爬取与存储
四、IP地址归属地查询
一、亚马逊商品页面爬取
找一个页面,如下
url = "https://www.amazon.cn/dp/B07FQKB4TM?_encoding=UTF8&ref_=sa_menu_kindle_l3_ki"
使用之前的通用代码框架,会发现产生异常:
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
#如果状态不是200,引发HTTPError异常
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常'
if __name__ == "__main__":
url = "https://www.amazon.cn/dp/B07FQKB4TM?_encoding=UTF8&ref_=sa_menu_kindle_l3_ki"
print(getHTMLText(url))
查看其返回状态为503
import requests
url = "https://www.amazon.cn/dp/B07FQKB4TM?_encoding=UTF8&ref_=sa_menu_kindle_l3_ki"
r = requests.get(url,timeout=30)
print(r.status_code)
print(r.request.headers)
r.encoding = r.apparent_encoding
print(r.text)
可以看 到如下信息:
此时我们需要考虑在get中使用一个user-agent参数


import requests
url = "https://www.amazon.cn/dp/B07FQKB4TM?_encoding=UTF8&ref_=sa_menu_kindle_l3_ki"
try:
kv = {'user-agent':'Mozilla/5.0'}
r1 = requests.get(url)
r2 = requests.get(url,headers=kv)
print(r1.status_code)
print(r1.request.headers)
print('\n')
print(r2.status_code)
print(r2.request.headers)
r2.raise_for_status()
r2.encoding = r2.apparent_encoding
#print(r2.text)
except:
print('爬取失败')
对比结果如下:
这样就能正常爬取了。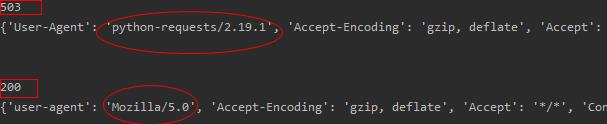
二、百度/360搜索关键字提交
百度的关键词接口:
http://www.baidu.com/s?wd=keyword
360的关键词接口:
http://www.so.com/s?q=keyword
具体用法见下面实例
百度:
import requests
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
360:
import requests
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
三、网络图片的爬取与存储
首先,找个目标图片的web地址。
然后就是使用requests爬取,使用os库进行相关存储操作。
全部示例代码如下:
import requests
import os
url = "https://c-ssl.duitang.com/uploads/item/201809/12/20180912231200_jPuyW.jpeg"
root = "D:\\pics\\"
path = root url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
四、IP地址归属地查询
最关键的是知道目标网址,然后输入相关需要查询的内容。
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url 'www.joinquant.com')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
总结:
以上示例都相对简单,总体上就是知道一个网址,然后使用requests进行请求,得到一个Response对象。对这个对象的处理,我们仅仅是显示打印。这远远满足不了要求。