扯个闲话,最近总是失眠,阿西巴,我需要来一打钞票安慰一下。
不过,自从来到聚宽以后,生活变得其实挺有趣的。有时候,想让生活变得有意义,做点有趣的即可。昨天晚上翻看了一下自已发在聚宽的帖子,第一条却是一个询问是API如何下载的问题。刚来聚宽,差点被这种高科技感的页面吓跑。
最近搞了个“三进兵策略”。不少宽友问如何选出更多适合这个策略的标的。我只能悄悄的告诉各位:我也不知道!这是大实话。策略里的几只标的,是经过观察MA45均线上价格的波动而得到的,最终选出这几只来做交易,当时还发现适合该策略的有“乐视网”,我一脚把它从股池里踢了出去(现在还脚疼呢)。在回测的过程中,其我也一直在尝试利用研究里的代码选出合适的标的,但是,不是说短线上穿长线就有机会的,因为长线同样会对价格有*作用。所以呢,最近还在研究选股这方面。
周五,稍微有那么一丢丢的小累。先更新一个短一点的机器学习笔记吧。大概今天晚上要好好的睡一觉了。
上一节中,了解了什么是标准线性模型与什么是岭回归。并且也知道岭回归存在一种被叫做L2正则化的约束。
除了Ridge,还有一种正则化的线性回归是lasso。与岭回归相同,使用lassob也是约束系数使其接近于0.但用到的方法不同,叫作L1正则化。L1正则化的结果是,使用lasso某些系数刚好为0。这说明某些特征被模型完全忽略。这可以看作是一种自动化的特征选择。某些系数刚好为0,这样模型量多容易解释,也可以带刺模型最重要的特征。
lasso模块的使用在linear_model下的Lasso中。
备注:mgleran中的数据是用来展示的,不与机器学习的sklern模块相重叠。
*mgleran请使用pip install mglearn命令。
# 在学习之前,先导入这些常用的模块import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport mglearn
接下来,我们将lasso应用在扩展的波士顿房价数据集上:
# 导入lasso模块from sklearn.linear_model import Lasso# 导入 train_test_split 模块 from sklearn.model_selection import train_test_split# 导入波士顿房价数据X, y = mglearn.datasets.load_extended_boston()# 将数据分为训练集与测试集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)# 实例化lasso对象,并对训练集数据进行训练lasso = Lasso().fit(X_train, y_train)
print('lasso在训练集的评估分数:', lasso.score(X_train, y_train))print('lasso在测试集的评估分数:', lasso.score(X_test, y_test))print('lasso模型保存的特征数量:', np.sum(lasso.coef_ != 0))lasso在训练集的评估分数: 0.29323768991114607lasso在测试集的评估分数: 0.20937503255272294lasso模型保存的特征数量: 4
结果显示,Lasso在训练集和测试集上的表现都不好,这说明这个模型存在欠拟合的现象。
当显示某数据的特征(斜率)是0的时候,表示是被模型忽略的。这里非0的特征数量只有4个,说明有过多的特征被忽略了。
为了降低欠拟合,需要降低alpha参数,也就是让模型显得“更复杂一点”。除了这么做,还需要增加max_iter参数,并适当修改它的值。该值表示运行迭代的最大次数。
# 降低alpha的值,增大max_iter的值lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)print('lasso001在训练集的评估分数:', lasso001.score(X_train, y_train))print('lasso001在测试集的评估分数:', lasso001.score(X_test, y_test))print('lasso001模型保存的特征数量:', np.sum(lasso001.coef_ != 0))lasso001在训练集的评估分数: 0.896506955975129lasso001在测试集的评估分数: 0.7656489887843521lasso001模型保存的特征数量: 33
由此可见,我调小了alpha的值,并加大了max_iter的值。模型的的评估结果表现变得好了许多,并且,使用到的特征数量也有所增加。
但需要注意的是,不能为了继续提高模型的泛化能力而将alpha的值改为0,这样该模型将与LinearRegression的结果类似,将出现过拟合的情况。
不信看下面:
# 让alpha的值接近于0lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)print('lasso00001在训练集的评估分数:', lasso00001.score(X_train, y_train))print('lasso00001在测试集的评估分数:', lasso00001.score(X_test, y_test))print('lasso00001模型保存的特征数量:', np.sum(lasso00001.coef_ != 0))lasso00001在训练集的评估分数: 0.9510610436181262lasso00001在测试集的评估分数: 0.6403098994161569lasso00001模型保存的特征数量: 94
这样的结果表明,模型在训练集表现相当优异,而在测试集的表现一般,这种现在是因为近拟合造成的,只能适配于训练的数据,而无法很好的适应于新的数据集。
接下来,就将alpha不同值情况下,模型的泛化能力结果图示化展示现在,以方便大家理解。
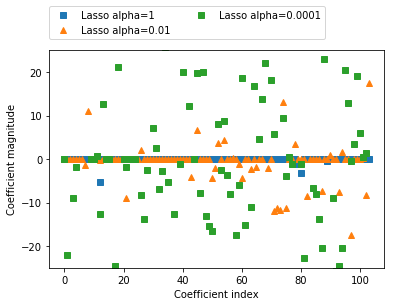
plt.plot(lasso.coef_, 's', label='Lasso alpha=1')
plt.plot(lasso001.coef_, '^', label='Lasso alpha=0.01')
plt.plot(lasso00001.coef_, 's', label='Lasso alpha=0.0001')
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel('Coefficient index')
plt.ylabel('Coefficient magnitude')
plt.show()从上图可以看出,当alpah的值越小时,将有越多的系数在0附近。
在实践中,岭回归与套索回归首先岭回归。但是,如果特征特别多,而某些特征更重要,具有选择性,那就选择Lasso可能更好。
scikit-learn还提供了ElasticNet类,结合了Lasso和Ridge的惩罚项。在实践中,这种结合的效果最好,不过代价是要调节两个参数:一个用于L1正则化,一个用于L2正则化。
上一节中,了解了什么是标准线性模型与什么是岭回归。并且也知道岭回归存在一种被叫做L2正则化的约束。
除了Ridge,还有一种正则化的线性回归是lasso。与岭回归相同,使用lassob也是约束系数使其接近于0.但用到的方法不同,叫作L1正则化。L1正则化的结果是,使用lasso某些系数刚好为0。这说明某些特征被模型完全忽略。这可以看作是一种自动化的特征选择。某些系数刚好为0,这样模型量多容易解释,也可以带刺模型最重要的特征。
lasso模块的使用在linear_model下的Lasso中。
# 在学习之前,先导入这些常用的模块import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport mglearn
接下来,我们将lasso应用在扩展的波士顿房价数据集上:
# 导入lasso模块from sklearn.linear_model import Lasso# 导入 train_test_split 模块 from sklearn.model_selection import train_test_split# 导入波士顿房价数据X, y = mglearn.datasets.load_extended_boston()# 将数据分为训练集与测试集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)# 实例化lasso对象,并对训练集数据进行训练lasso = Lasso().fit(X_train, y_train)
print('lasso在训练集的评估分数:', lasso.score(X_train, y_train))print('lasso在测试集的评估分数:', lasso.score(X_test, y_test))print('lasso模型保存的特征数量:', np.sum(lasso.coef_ != 0))lasso在训练集的评估分数: 0.29323768991114607 lasso在测试集的评估分数: 0.20937503255272294 lasso模型保存的特征数量: 4
结果显示,Lasso在训练集和测试集上的表现都不好,这说明这个模型存在欠拟合的现象。
当显示某数据的特征(斜率)是0的时候,表示是被模型忽略的。这里非0的特征数量只有4个,说明有过多的特征被忽略了。
为了降低欠拟合,需要降低alpha参数,也就是让模型显得“更复杂一点”。除了这么做,还需要增加max_iter参数,并适当修改它的值。该值表示运行迭代的最大次数。
# 降低alpha的值,增大max_iter的值lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)print('lasso001在训练集的评估分数:', lasso001.score(X_train, y_train))print('lasso001在测试集的评估分数:', lasso001.score(X_test, y_test))print('lasso001模型保存的特征数量:', np.sum(lasso001.coef_ != 0))lasso001在训练集的评估分数: 0.896506955975129 lasso001在测试集的评估分数: 0.7656489887843521 lasso001模型保存的特征数量: 33
由此可见,我调小了alpha的值,并加大了max_iter的值。模型的的评估结果表现变得好了许多,并且,使用到的特征数量也有所增加。
但需要注意的是,不能为了继续提高模型的泛化能力而将alpha的值改为0,这样该模型将与LinearRegression的结果类似,将出现过拟合的情况。
不信看下面:
# 让alpha的值接近于0lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)print('lasso00001在训练集的评估分数:', lasso00001.score(X_train, y_train))print('lasso00001在测试集的评估分数:', lasso00001.score(X_test, y_test))print('lasso00001模型保存的特征数量:', np.sum(lasso00001.coef_ != 0))lasso00001在训练集的评估分数: 0.9510610436181262 lasso00001在测试集的评估分数: 0.6403098994161569 lasso00001模型保存的特征数量: 94
这样的结果表明,模型在训练集表现相当优异,而在测试集的表现一般,这种现在是因为近拟合造成的,只能适配于训练的数据,而无法很好的适应于新的数据集。
接下来,就将alpha不同值情况下,模型的泛化能力结果图示化展示现在,以方便大家理解。
plt.plot(lasso.coef_, 's', label='Lasso alpha=1')plt.plot(lasso001.coef_, '^', label='Lasso alpha=0.01')plt.plot(lasso00001.coef_, 's', label='Lasso alpha=0.0001')plt.legend(ncol=2, loc=(0, 1.05))plt.ylim(-25, 25)plt.xlabel('Coefficient index')plt.ylabel('Coefficient magnitude')plt.show()从上图可以看出,当alpah的值越小时,将有越多的系数在0附近。
在实践中,岭回归与套索回归首先岭回归。但是,如果特征特别多,而某些特征更重要,具有选择性,那就选择Lasso可能更好。
scikit-learn还提供了ElasticNet类,结合了Lasso和Ridge的惩罚项。在实践中,这种结合的效果最好,不过代价是要调节两个参数:一个用于L1正则化,一个用于L2正则化。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程