本文以我国2008年1月-2017年10月区间的10年期国债收益率为研究对象,选取了同时间区间内的若干常见宏观经济指标,通过机器学习中的主成分回归(principle component regression,PCR)等方法,分析了这些宏观经济指标对10年期国债收益率的影响程度。
一,国债收益率
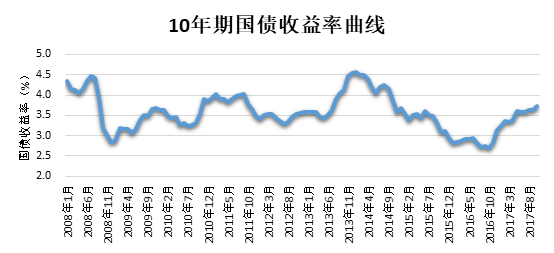
国债收益率是指投资于国债债券这一有价证券所得收益占投资总金额每一年的比率。在美国等发达的市场经济国家,国债收益率事实上已成为金融市场的基准利率,并成为投资者判断市场趋势的风向标月。10年期国债收益率在我国具有较强的代表性。2008年1月-2017年10月的10年期国债收益率变化参考图1所示,其中2013年7月-2016年10月,10年期国债收益率出现了较大的振幅。
图 1 10年期国债收益率曲线(2008年1月-2017年10月)
二,常见宏观经济指标
(一)采购经理人指数(PMI)
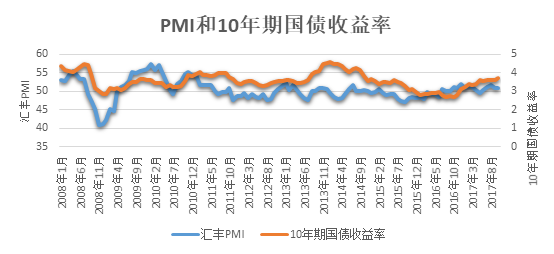
采购经理人指数(PMI)分为制造业和非制造业两种。制造业采购经理人指数主要衡量在生产、新订单、商品价格、存货、雇员、订单交货、新出口订单和进口等8个方面状况的指数,是经济先行指标中一项非常重要的附属指标;非制造业采购经理人指数包括服务业PMI,也有一些国家建立了建筑业PMI。PMI为每月第一个公布的重要经济数据,其反映的经济状况也较全面。通过比较2008年1月-2017年10月的汇丰PMI和10年期国债收益率的走势,参考图2,可以发现,在大多数情况下,PMI和10年期国债收益率的变化是同向的,但在2013年7月-2014年5月,PMI和10年期国债收益率的变化出现了明显背离的情况。因此,可以认为,除了PMI以外,还有一系列其他复杂的因素在影响10年期国债收益率的变化。
图 2 PMI和10年期国债收益率
(二)宏观经济景气指数
宏观经济景气指数,是在既有的统计指标基础之上,筛选出具有代表性的指标,建立一个经济监测指标体系,并以此建立各种指数或模型来描述宏观经济的运行状况和预测未来走势。对于很多描述宏观经济的指标,比如GDP、股票指数、利率等等,选出其中比较有代表性的一些,把它变成一个指数。宏观经济景气指数分为三种指标,分别是一致指标,先行指标与滞后指标。一致指标的意思就是,如果这个指标好,就代表现在宏观经济好,这个指标不好,就说明宏观经济不好。先行指标的意思就是,这个指标好的时候宏观经济不一定好,但之后一段时间可能会变得比较好,这个指标不好的时候宏观经济不一定不好,但之后一段时间可能会变得不好,具有预测性,因此叫做先行指标。滞后指标的意思就显而易见了,这个指标是在得知宏观经济好坏之后才能得到的指标,这个指标高,则说明之前一段时间宏观经济比较景气,这个指标低,则说明之前一段时间宏观经济不太景气。与指标相对应的分别为宏观经济景气一致指数、宏观经济景气先行指数和宏观经济景气滞后指数。
(三)居民消费价格指数(CPI)
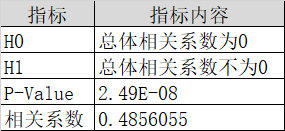
CPI是物价的相关指标,这个指标其实就是一篮子商品价格的加权平均值。对国债收益率曲线的影响因素研究指出(孙梅,2016),CPI往往是国家制*币政策的依据,也是对债券市场影响最大的几个指标之一。债券作为一款金融产品,想要吸引到投资人,必须能够保证投资人资产保值甚至是升值,换言之,就是债券的收益率需要高于CPI指数,才会有人愿意买。CPI和通货膨胀情况正相关,很多国家采用用CPI衡量通货膨胀的程度,债券的收益率近似等于通货膨胀率加上实际利率,即r_bond ≈ CPI r_real,通货膨胀与债券的收益率紧密相关。另一方面,国家需要保证货币价值的稳定,如果CPI大幅变动的话,一般央行会通过调整基准利率,准备金率,或者公开市场操作来稳定市场,这些操作影响了债券的供求,又会导致债券收益率的变化。取样本区间2008年1月—2017年10月的CPI和10年期国债收益率数据,检验其相关系数的显著性,结果参考表1所示。由表1可知,原假设H0不成立,即CPI和10年期国债收益率具有一定的相关性。
表 1 CPI与10年期国债收益率相关系数显著性检验
(四)货币政策
货币政策是央行调节宏观经济所实施的各种方法和措施,对国债收益率曲线的影响非常明显。货币政策包括调整基本准备金率、基准利率和公开市场操作等,主要是采取各种措施来控制市场上的货币供应量。央行的货币净投放量及M2是反映货币政策的重要指标。
(五)国民生产总值(GDP)
国民生产总值(GDP)也是宏观经济的一个重要的指标。债券市场一般可以提前反映出宏观经济的走向,国债收益率曲线是宏观经济的晴雨表。关于宏观经济指标对于国债收益率的影响的研究提出(孙梅,2016),一般情况下,国债的收益率同GDP增速正相关。因为经济环境繁荣时,投资人对收益要求普遍较高。这个效应作用于国债市场,使得投资者对于国债的收益预期比较高,债券价格就会降低。
三,实证分析
(一)数据准备
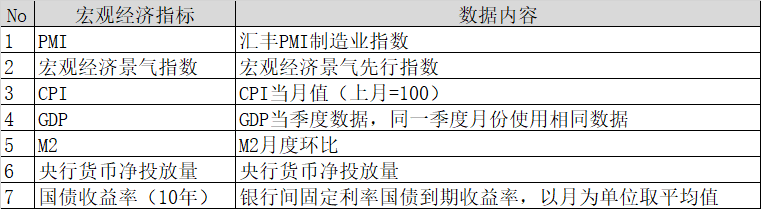
取样本区间2008年1月—2013年6月的宏观经济指标数据和10年期国债收益率(月度)作为分析对象,具体参考表2:
表 2 宏观经济指标数据和10年期国债收益率
(二)因子提取
由于宏观经济指标之间的关联性较大,为了规避多重共线性,本文使用主成分分析方法对表2的1-6项因子进行降维,进而提取影响10年期国债收益率的因子。对上述因子做碎石检验,结果参考图3,进而确定主成分因子数为5。碎石检验的程序可用R语言简单实现,示例如下:
library(psych)
fa.parallel(ratio[,2:7],fa="pc",n.iter=100,show.legend=FALSE,main="碎石检验")
图 3 因子碎石检验结果
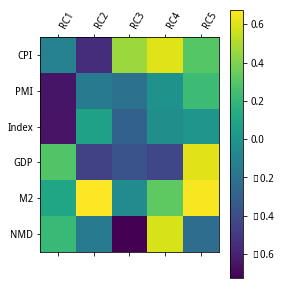
对主成分RC1-RC5做主成分得分分析,分析结果可参考pca.components,pca.explained_variance_ratio等结果数值,
其可视化结果可参考图4:
图4 主成分分析结果
分析结果可知:
1.主成分RC1与指标PMI及宏观经济景气指数高度相关,主成分RC2与CPI,M2高度相关,主成分RC3,R*与央行货币净投放量高度相关。
2.主成分RC1解释了宏观经济指标的33%的方差,而RC2—R*分别解释了21%,17%,15%,剩余的则由RC5来解释。
如果采用R语言,则可使用方差极大旋转的主成分分析,其结果数据比用python实现更加丰富,比如成分公因子方差(h2),即主成分对每个变量的方差解释度。R语言的实现方法示例如下:
pca <- principal(ratio[,2:7],nfactors=5,rotate = "varimax")
笔者的能力有限,没有研究出在sklearn中如何使用方差极大旋转,没能做到和R语言一样的效果。
(三)回归模型
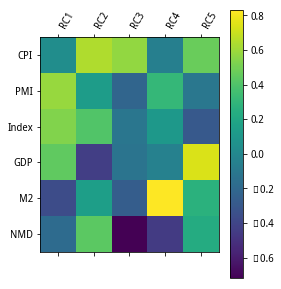
为解释上述宏观经济指标对10年期国债收益率的影响,使用国债收益率(10年)作为被解释变量,上述主成分RC1-RC5作为解释变量,建立Lasso回归模型。主成分RC1-RC5对国债收益率的影响训练集打分为0.69,测试集打分为0.53。同理,取样本区间2013年7月—2017年10月的宏观经济指标数据和10年期国债收益率(月度)作为分析对象,可视化结果可参考图5,得出主成分RC1-RC5对国债收益率的影响训练集打分为0.42,测试集打分为0.22。
图5 主成分分析结果
四,结论
对2008年1月-2013年6月与2013年7月-2017年10月的样本数据分析结果进行对比,可知:
1,2008年1月-2013年6月期间,对国债收益率的主要影响因素是PMI,宏观经济景气指数及CPI,且对国债收益率的影响程度较大。
2,2013年7月-2017年10月期间,对国债收益率的主要影响因素不仅仅是PMI,宏观经济景气指数及CPI,央行货币净投放量对国债收益率也产生了一定的影响。这一点和2013年下半年的“钱荒”导致10年期国债收益率飙升的报道有一定的吻合,但从打分的数值来看,上述因素仅仅在一定程度上影响了国债收益率的变化。
3,2008年1月-2017年10月期间,宏观经济指标中的GDP和M2不是影响国债收益率变化的直接因素。
参考文献:
1 梁雁,2016:货币政策对国债收益率曲线的影响及传导机制研究,金融观察,2016年第2期
2 孙梅,2016:我国国债收益率曲线实证研究,北京外国语大学硕士学位论文,2016
本文用到的数据链接如下:
提取码:sja3
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCA
#df=pd.read_csv("Bond/Bond2008.csv")df=pd.read_csv("Bond/Bond2013.csv")#df=pd.read_csv("Bond/Bond.csv")df.head()
.dataframe thead tr:only-child th { text-align: right; } .dataframe thead th { text-align: left; } .dataframe tbody tr th { vertical-align: top; }
| Date | CPI | PMI | index | gdp | M2 | volume | ratio | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2013/7/1 | 102.7 | 47.7 | 100.2 | 138752.53 | -0.0021 | 1242 | 3.6344 |
| 1 | 2013/8/1 | 102.6 | 50.1 | 99.9 | 138752.53 | 0.0086 | 2150 | 3.9130 |
| 2 | 2013/9/1 | 103.1 | 50.2 | 99.6 | 138752.53 | 0.0152 | 160 | 4.0485 |
| 3 | 2013/10/1 | 103.2 | 50.9 | 99.5 | 201257.30 | -0.0067 | -404 | 4.1133 |
| 4 | 2013/11/1 | 103.0 | 50.8 | 99.6 | 201257.30 | 0.0085 | 560 | 4.4633 |
X_train = df.iloc[:,1:7]
scaler = StandardScaler()scaler.fit(X_train)X_scaled = scaler.transform(X_train)
##PCA模型实例化#参数设置#<n_components>:#意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n,缺省时默认为None。#类型:int 或者 string,所有成分被保留。#赋值为int,比如n_components=1,将把原始数据降到一个维度。#赋值为string,比如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。#<copy>:#类型:bool,True或者False,缺省时默认为True。#意义:表示是否在运行算法时,将原始训练数据复制一份。#若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;#若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。#<whiten>:#类型:bool,缺省时默认为False#意义:白化,使得每个特征具有相同的方差。pca = PCA(n_components=5)#pca = PCA(n_components='mle',whiten='true')#pca = KernelPCA(n_components=5, kernel='rbf')##PCA模型训练(无监督学习,所以y不需要)pca.fit(X_scaled)
PCA(copy=True, iterated_power='auto', n_components=5, random_state=None, svd_solver='auto', tol=0.0, whiten=False)
##将数据X转换成降维后的数据X_pca = pca.transform(X_scaled)print("Original shape: {}".format(str(X_scaled.shape)))print("Reduced shape: {}".format(str(X_pca.shape)))#返回保留的特征数print("PCA n_components:\n{}".format(pca.n_components_))#返回具有最大方差的成分print("PCA components:\n{}".format(pca.components_))#返回所保留的n个成分各自的方差百分比print("PCA explained_variance_ratio:\n{}".format(pca.explained_variance_ratio_))#返回所保留的n个成分各自的方差print("PCA explained_variance:\n{}".format(pca.explained_variance_))Original shape: (52, 6) Reduced shape: (52, 5) PCA n_components: 5 PCA components: [[ 0.03997224 0.58813302 0.53656253 0.4507966 -0.36062952 -0.17700618] [ 0.64596642 0.13638855 0.40837213 -0.42958799 0.15061002 0.4360373 ] [ 0.58017397 -0.2174981 -0.11289298 -0.12676596 -0.26365061 -0.71956005] [-0.05170277 0.30910202 0.10865542 -0.04108888 0.82886746 -0.44862813] [ 0.47747007 -0.10714183 -0.2848768 0.74344987 0.26966008 0.2322798 ]] PCA explained_variance_ratio: [0.32019001 0.21324977 0.15580839 0.14667041 0.10302334] PCA explained_variance: [1.92114008 1.2794986 0.93485032 0.88002246 0.61814004]
components = np.transpose(pca.components_)plt.matshow(components, cmap='viridis')plt.colorbar()plt.yticks(np.arange(6),["CPI","PMI","Index","GDP","M2","NMD"])plt.xticks(np.arange(pca.n_components_),["RC1","RC2","RC3","R*","RC5"],rotation=60,ha="left")
([<matplotlib.axis.XTick at 0x7ffb21efdb00>, <matplotlib.axis.XTick at 0x7ffb21efd4a8>, <matplotlib.axis.XTick at 0x7ffb21f21860>, <matplotlib.axis.XTick at 0x7ffb21ee7588>, <matplotlib.axis.XTick at 0x7ffb21ee7ac8>], <a list of 5 Text xticklabel objects>)
# 获得新的主成分矩阵# 行:特征样本# 列:RC1~RC5rc_matrix = X_scaled.dot(components)
df_rc = pd.DataFrame(data=rc_matrix,columns=['RC1', 'RC2', 'RC3','R*','RC5'])
df_new = df.join(df_rc)
X_trainval = df_new.loc[:,['RC1','RC2','RC3','R*','RC5']]y_trainval = df_new.loc[:,"ratio"]
from sklearn.model_selection import train_test_splitX_train,X_valid,y_train,y_valid = train_test_split(X_trainval,y_trainval,random_state=0)
from sklearn.linear_model import Lassolasso = Lasso(alpha=0.01, max_iter=100000)lasso.fit(X_train, y_train)print("Training set score: {:.2f}".format(lasso.score(X_train, y_train)))print("Testing set score: {:.2f}".format(lasso.score(X_valid, y_valid)))print("Intercept: {:.2f}".format(lasso.intercept_))print(lasso.coef_)Training set score: 0.42 Testing set score: 0.22 Intercept: 3.62 [-0.02053184 0.28152166 -0. 0.02368279 -0.1134919 ]

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
4秒后跳转登录页面...