因子分析API是聚宽网为量化编程者提供的重要工具。但作为量化初学者来说,代码基础薄弱,编程思维欠缺,导致量化程序难以迅速读懂,常常导致心情低落甚至放弃量化学习。比如本人近期在学习的一个帖子【量化课堂】东方证券研报实践——动态情景多因子Alpha模型,评论中一些宽友反映看不懂。本人为一个量化程序初学者,发现若可以直接观察程序每一步结果,可快速建立编辑逻辑,对于程序学习大有裨益的。
为求直观看到每一行程序的结果,我利用“投资研究”界面复现程序,步步拆解,可以实现程序结果可视化。但是因子分析API是程序封装好的类,没办法获得中间代码结果。比如calc 的获取data数据并进一步处理,这对初学者来讲过于抽象。由于初学者对data数据结构的不熟悉,大量的脑力用于记忆及处理data数据,这简直是无法承受的痛苦。
jupyter中不能直接展示data数据,为了解决初学者对data数据的理解及程序复现的问题,我复现了因子分析API对data数据的获取过程,通过此代码可以直观看到data数据结构。
'''
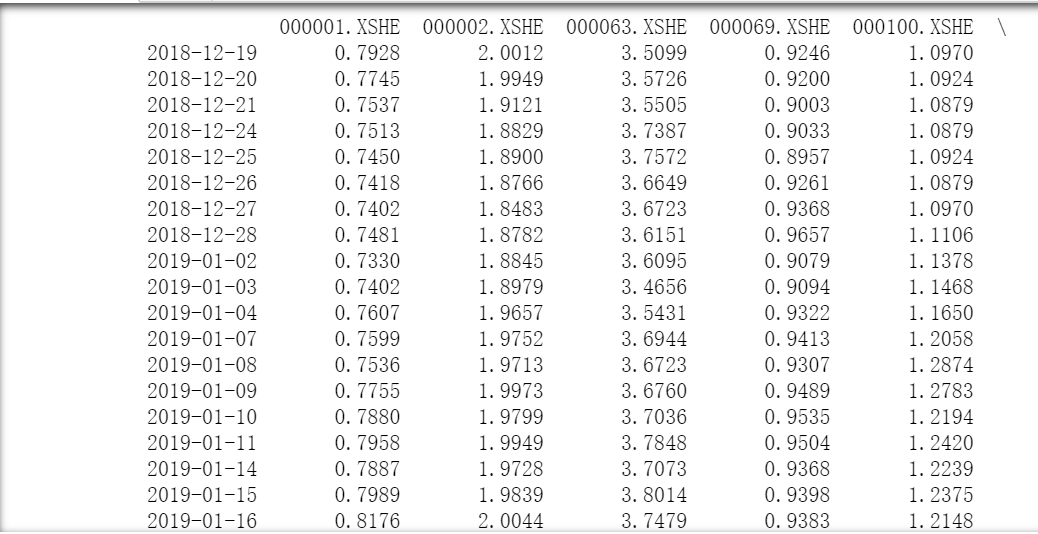
模拟calc获得data的过程。data 参数获取通过 max_window 和 dependencies 定义。data是测试用的数据,所以全部基于沪深300数据。
data 是一个 dict, key 是 dependencies 中的因子名称, DataFrame 的 column 是股票代码,
DataFrame 的 index 是一个时间序列,结束时间是当前时间, 长度是 max_window;
'''
import jqdata
import pandas as pd
from jqfactor import Factor, calc_factors
import datetime
import numpy as np
from statsmodels.api import OLS
import statsmodels.api as sm
import math
#组建模拟因子分析获取data类
class imitate_get_data:
def __init__(self,max_window,dependencies):
self.max_window = max_window
self.dependencies = dependencies
self.universe = self.get_universe()
self.list_window = self.get_window_list()
#1.获取沪深300指数中的未停盘股票。日期为本日的前一个交易日。为什么不是其他日期?本来就是模拟data数据格式,没必要对日期有过多要求。
def get_universe(self):
#1.1获取最近一个交易日的时间。通过get_price为空判断是否为交易日,否的话需要向前步进。
the_time = (datetime.datetime.now()-datetime.timedelta(days = 1)).strftime('%Y-%m-%d') #获取前一天的日期
trading_day = get_price('000333.XSHE', start_date=the_time, end_date=the_time, frequency='daily',fields=['open'], fq='pre')
while trading_day.empty == True:
the_time = (datetime.datetime.strptime(the_time, '%Y-%m-%d')-datetime.timedelta(days = 1)).strftime('%Y-%m-%d')
trading_day = get_price('000333.XSHE', start_date=the_time, end_date=the_time, frequency='daily',fields=['paused'], fq='pre')
#1.2获取最近一个交易日的沪深300指数成分股。
universe0 = get_index_stocks('000300.XSHG', the_time)
#1.3获取非停盘的股票代码
paused_stocks = get_price(universe0, start_date = the_time, end_date = the_time, frequency='daily',\
fields=['paused'], skip_paused=False, fq='pre', count=None)['paused']
universe = [i for i in universe0 if paused_stocks[i][the_time] == 0.0]
return universe
#2.获取max_window决定的交易日list
#2.1识别某个时间是否是交易日
def judge_trading_time(self,time1):
trading_day = get_price('000333.XSHE', start_date=time1, end_date=time1, frequency='daily',\
fields=['paused'], skip_paused=False, fq='pre', count=None)
#x返回值是1说明这个时间为交易日
if trading_day.empty == True:
x = 0
else:
x = 1
return x
#2.2获取由max_window决定的交易日list
def get_window_list(self):
date1 = (datetime.datetime.now()-datetime.timedelta(days = 1)).strftime('%Y-%m-%d') #获取前一天的日期
#date1是前一天的日期,首先识别其是否为交易日,如非交易日,循环向前至交易日为止。
while self.judge_trading_time(date1) == 0:
date1 = (datetime.datetime.strptime(date1, '%Y-%m-%d')-datetime.timedelta(days = 1)).strftime('%Y-%m-%d')
list_window_time = []
list_window_time.append(date1)
date2 = (datetime.datetime.strptime(date1, '%Y-%m-%d')-datetime.timedelta(days = 1)).strftime('%Y-%m-%d')
#对列表元素数量进行循环,小于5时添加元素,需保证添加的日期字符串为交易日。
while len(list_window_time) < self.max_window:
if self.judge_trading_time(date2) == 0:
date2 = (datetime.datetime.strptime(date2, '%Y-%m-%d')-datetime.timedelta(days = 1)).strftime('%Y-%m-%d')
else:
list_window_time.append(date2)
date2 = (datetime.datetime.strptime(date2, '%Y-%m-%d')-datetime.timedelta(days = 1)).strftime('%Y-%m-%d')
return list_window_time[::-1]
#3获取单个因子的dataframe函数,因子类型不同,所以要分类获取。现在主要实现了行业因子、财务指标因子、价格因子。
#3.1定义行业因子函数。因子名称是行业代码,因子值是一个哑变量,如果某股票属于某行业,则返回1,否则,返回0。
def get_hy_data(self,dependency):
hy_data = pd.DataFrame(index = self.list_window,columns = self.universe)
for a in self.list_window:
list_hy = get_industry_stocks(dependency, date=a) #获取由max_window交易日的行业列表
for b in self.universe:
if b in list_hy:
hy_data.loc[a,b] = 1
else:
hy_data.loc[a,b] = 0
return hy_data
#3.2定义财务因子函数。原始数据为季度数据,可以通过在因子后加『_1』的方式, 获取前几个季度的财务指标。可以通过在因子后加『_y1』的方式, 获取前几年的财务指标。
#传入max_window交易日列表中的日期,分别查找对应日期的季度数据即可。
def get_financial_data(self,dependency):
#将query对象合成为字典,方便合成query语句。
valuation_key = ['capitalization','circulating_cap','market_cap','circulating_market_cap','turnover_ratio','pe_ratio','pe_ratio_lyr','pb_ratio','ps_ratio','pcf_ratio']
valuation_value = [valuation.capitalization,valuation.circulating_cap,valuation.market_cap,valuation.circulating_market_cap,valuation.turnover_ratio,valuation.pe_ratio,valuation.pe_ratio_lyr,valuation.pb_ratio,valuation.ps_ratio,valuation.pcf_ratio]
valuation_dict = dict(zip(valuation_key, valuation_value))
if dependency in valuation_key:
q = query(
valuation.code,valuation_dict[dependency]
).filter(valuation.code.in_(self.universe))
#遍历max_window决定的日期列表,并形成对应日期的dependency矩阵,对矩阵依行进行合并。
df1 = pd.DataFrame()
for a in self.list_window:
get_financial_index = get_fundamentals(q, a)
get_financial_index.index = get_financial_index['code'].tolist()
get_financial_index.drop('code',axis=1, inplace=True)
list_window_time1 = []
list_window_time1.append(a)
get_financial_index.columns = list_window_time1
df1 = pd.concat([df1,get_financial_index.T],axis=0)
return df1
#3.3定义价量信息因子函数。 包含open\close\high\low\money\volume字段使用后复权的值。利用get_price函数应该可以获得数据。
def get_price_data(self,dependency):
return get_price(self.universe, end_date=self.list_window[-1], frequency='daily', fq='pre', count=len(self.list_window))[dependency]
#4.将dependencies因子分类,适用不同数据获取函数,形成最终dict格式的data模拟结果。
def get_calc_data(self):
calc_data = {}
hy_dependencies = ['HY001','HY002','HY003','HY004','HY005','HY006','HY007','HY008','HY009','HY010','HY011']
valuation_dependencies = ['capitalization','circulating_cap','market_cap','circulating_market_cap','turnover_ratio','pe_ratio','pe_ratio_lyr','pb_ratio','ps_ratio','pcf_ratio']
price_dependencies = ['open','close','high','low','volume','money']
for dependency in self.dependencies:
if dependency in hy_dependencies:
calc_data[dependency] = self.get_hy_data(dependency)
if dependency in valuation_dependencies:
calc_data[dependency] = self.get_financial_data(dependency)
if dependency in price_dependencies:
calc_data[dependency] = self.get_price_data(dependency)
return calc_data
大家可通过调用imitate_get_data(max_window,dependencies).get_calc_data()即可获取对应数据。
同时需要输入的参数有max_window及dependencies。我做了一个调用的示例,代码如下。
max_window = 21
dependencies = ['circulating_market_cap','pb_ratio','close','market_cap','HY001','HY002','HY003','HY004','HY005',
'HY006','HY007','HY008','HY009','HY010','HY011']
a_data = imitate_get_data(max_window,dependencies).get_calc_data()
print(a_data['pb_ratio'])
输出结果如下:
需要注意的是,以上代码仅模拟了行业因子,财务因子及价量信息因子。本代码仅供学习数据结构,应该完全可以模拟绝大部分情况。
获得data数据后,我们可以完全复现“def calc(self, data):”后面的数据操作,获得因子分析模拟结果,方便大家学习。再分享一个模拟的例子,复现因子分析api帮助的第一个函数,原始代码如下。
class MA5(Factor):
name = 'ma5'
# 每天获取过去五日的数据
max_window = 5
# 获取的数据是收盘价
dependencies = ['close']
def calc(self, data):
return data['close'][-5:].mean()
模拟返回值代码为
max_window = 5
dependencies = ['close']
a_data = imitate_get_data(max_window,dependencies).get_calc_data()
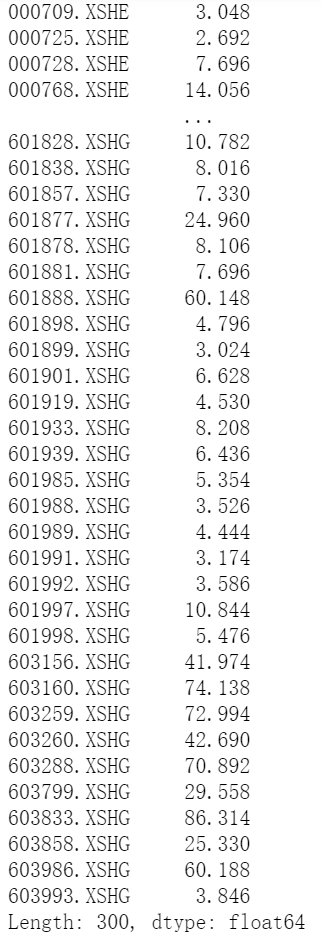
print(a_data['close'][-5:].mean())
输出结果如下图:
本文章希望对大家有帮助,方法比较笨拙,也请广场高手多多指点。

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程