0. 说在前面:
在聚宽混了两个多月,自己借鉴许多大佬的思路和代码,搞了一个轮动周期的框架,跑了一下感觉一般,算是开始入门吧。
PS: 小弟今年大三金融,对计算机不太熟悉,有些代码如果写错了还请各位大佬多多指出,相互学习,多多交流!
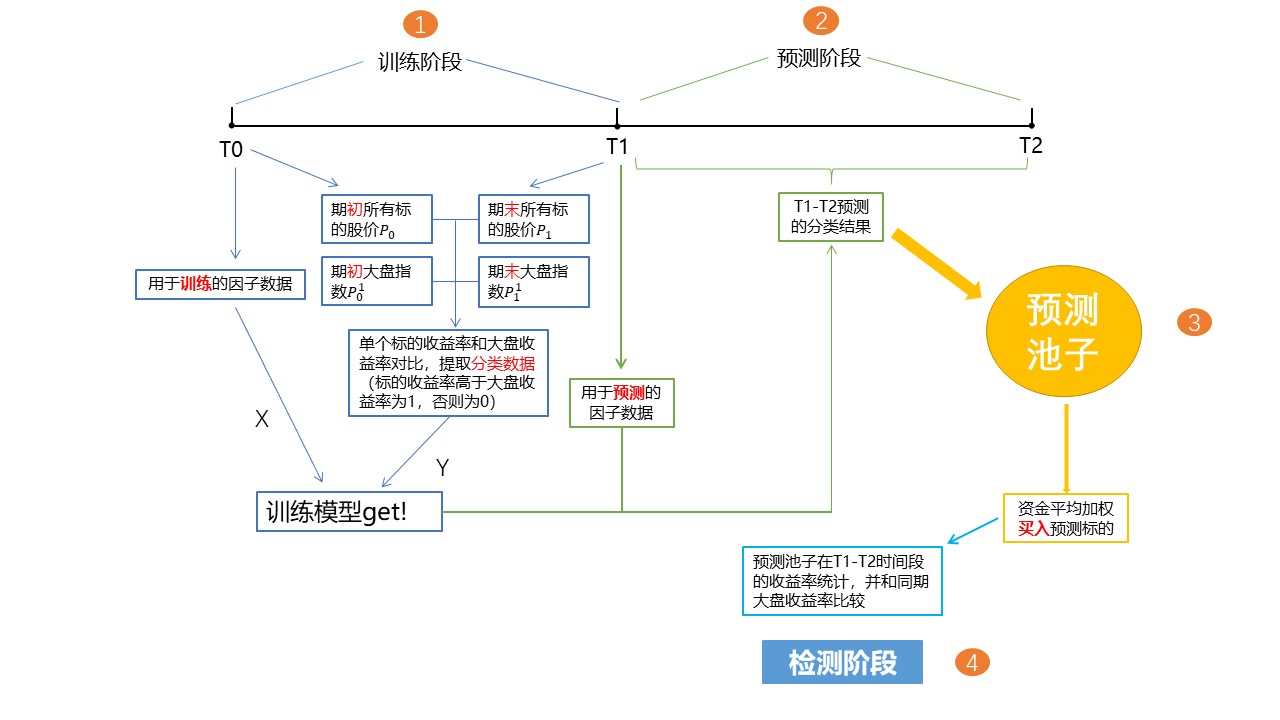
1. 轮动框架逻辑(下图)
(1) 时间跨度:2014-01-01 到 2019-03-01,以月为单位
(2) 标的池子选取:提取中证500作为训练和预测池子
(3) 因子提取:61个因子:有基本面和技术面,基本面有盈利能力、运营能力、长/短周期偿债 能力、估值因子等;技术面就借鉴之前西安交大SVM那份report的一些技术因子
(4) 数据预处理:缺失值处理、去极值、中性化、标准化(数据预处理的一些函数我借鉴了西交大SVM的那份report,笔芯!!)
(5) 训练: 大家可以print完“参数”后,再print一下“test_timing”(可能会好理解一点)。在T0取得因子值,在T0-T1取得中证500标的的收益率,然后对同期中证500指数的收益率做对比,标的收益率大于指数收益率的分类值为1,否则为0。对因子值和分类值作训练。
(6) 预测:在T1获得标的池子的因子值,根据训练set得出来的分类模型和T1的因子值,预测T1-T2标的池子的分类结果(预测有哪些标的在T1-T2会跑赢大盘),然后把预测分类值为1的标的提取出来,组成新的标的池子,假设资金平均加权在T1时间点购入,到了T2后,算出预测池子的平均收益率。
(7) 算法套用:clf: sklearn 的 MLPClassifier;clf1: sklearn 的 SVM (鉴于clf算法在有些周期预测出来的分类结果都为0,这种情况下会套用SVM对T1因子值重新训练)
(8) 结果:模型预测的池子跑出来和大盘差不多,算是小白开始入门吧。
2. Results:
2.1 预测池子数量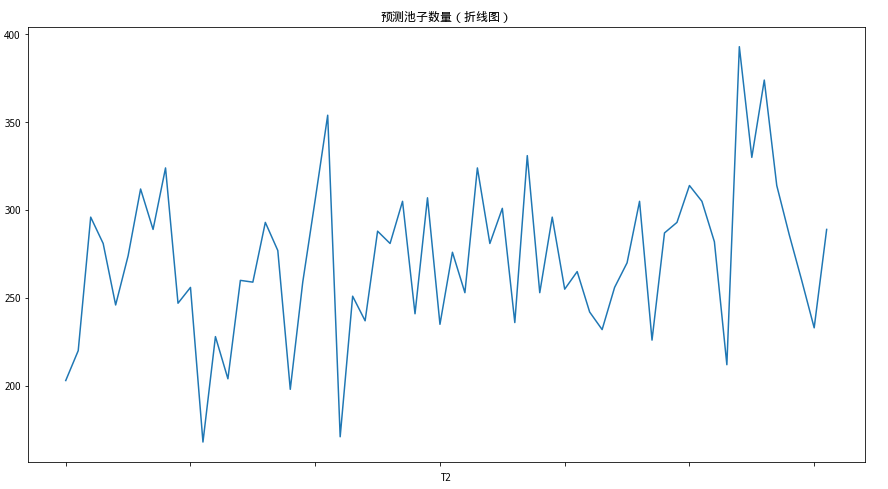
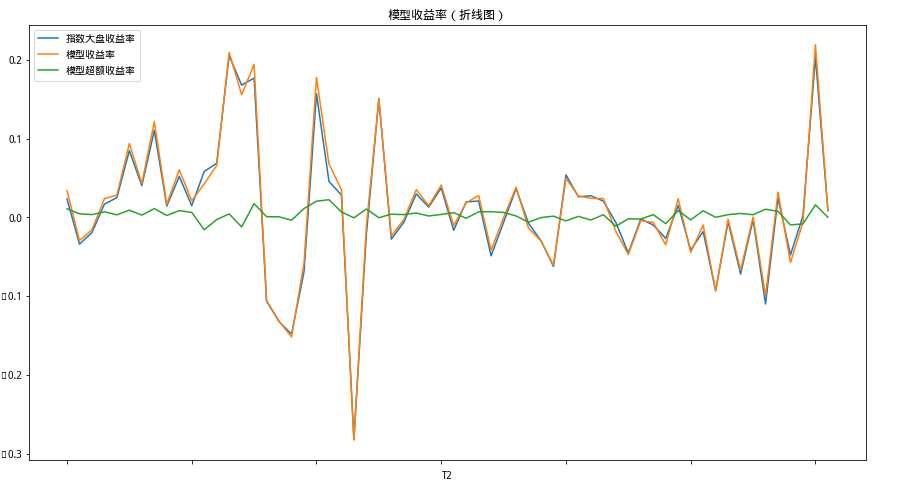
2.2 模型收益率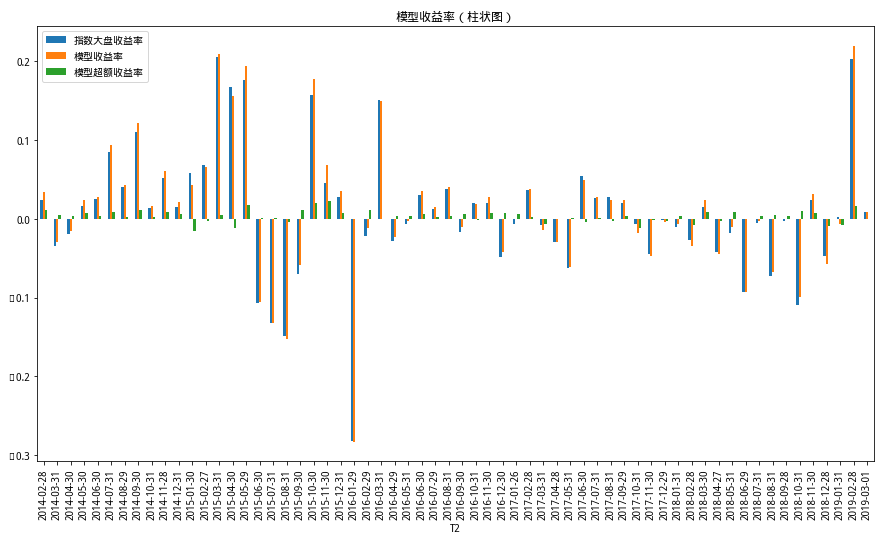
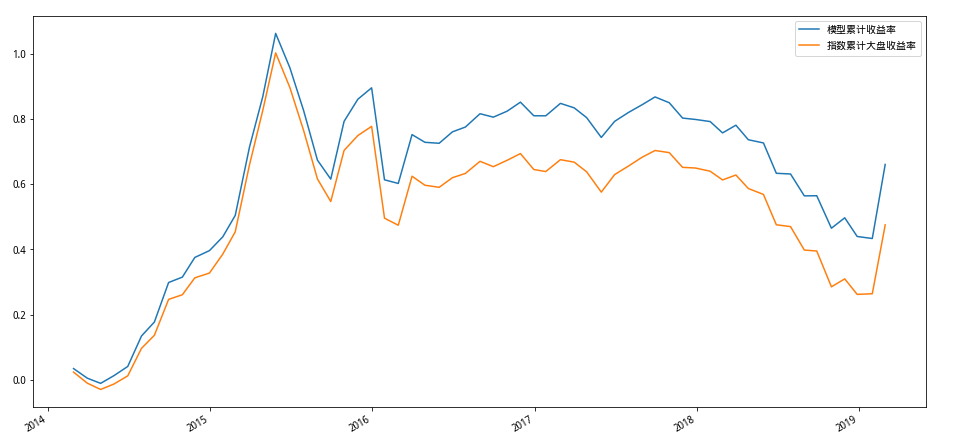
2.3 累计收益率
在聚宽混了两个多月,自己借鉴许多大佬的思路和代码,搞了一个轮动周期的框架,跑了一下感觉一般,算是开始入门吧。
PS: 小弟今年大三金融,对计算机不太熟悉,有些代码如果写错了还请各位大佬多多指出,相互学习,多多交流!
(1) 时间跨度:2014-01-01 到 2019-03-01,以月为单位
(2) 标的池子选取:提取中证500作为训练和预测池子
(3) 因子提取:61个因子:有基本面和技术面,基本面有盈利能力、运营能力、长/短周期偿债 能力、估值因子等;技术面就借鉴之前西安交大SVM那份report的一些技术因子
(4) 数据预处理:缺失值处理、去极值、中性化、标准化(数据预处理的一些函数我借鉴了西交大SVM的那份report,笔芯!!)
(5) 训练: 大家可以print完“参数”后,再print一下“test_timing”(可能会好理解一点)。在T0取得因子值,在T0-T1取得中证500标的的收益率,然后对同期中证500指数的收益率做对比,标的收益率大于指数收益率的分类值为1,否则为0。对因子值和分类值作训练。
(6) 预测:在T1获得标的池子的因子值,根据训练set得出来的分类模型和T1的因子值,预测T1-T2标的池子的分类结果(预测有哪些标的在T1-T2会跑赢大盘),然后把预测分类值为1的标的提取出来,组成新的标的池子,假设资金平均加权在T1时间点购入,到了T2后,算出预测池子的平均收益率。
(7) 算法套用:clf: sklearn 的 MLPClassifier;clf1: sklearn 的 SVM (鉴于clf算法在有些周期预测出来的分类结果都为0,这种情况下会套用SVM对T1因子值重新训练)
(8) 结果:模型预测的池子跑出来和大盘差不多,算是小白开始入门吧。
# 框架测试 v9 # 制作人:Howard董先森, wechat:dhl19988882,e-mail: 16hldong.stu.edu.cn# 以下是我站在巨人的肩膀上,加上自己的理解,整合出来的框架函数,小伙伴们copy并分享的时候记得给小弟一下credit就好~import warningswarnings.filterwarnings("ignore")'''导入函数库'''import pandas as pdimport numpy as npimport timeimport datetimeimport statsmodels.api as smimport pickleimport warningsfrom itertools import combinationsimport itertoolsfrom jqfactor import get_factor_valuesfrom jqdata import *from jqfactor import neutralizefrom jqfactor import standardlizefrom jqfactor import winsorizefrom jqfactor import neutralizeimport calendarfrom scipy import statsimport statsmodels.api as smfrom statsmodels import regressionimport csvfrom six import StringIOfrom jqlib.technical_analysis import *#导入pcafrom sklearn.decomposition import PCAfrom sklearn import svmfrom sklearn.model_selection import train_test_splitfrom sklearn.grid_search import GridSearchCVfrom sklearn import metricsimport matplotlib.dates as mdatesimport matplotlib.pyplot as pltimport seaborn as snsimport matplotlib.pyplot as pltfrom jqfactor import neutralize'''普通工具'''# 多重列表*函数def splitlist(b):alist = []a = 0for sublist in b:try: #用try来判断是列表中的元素是不是可迭代的,可以迭代的继续迭代for i in sublist:alist.append (i)except TypeError: #不能迭代的就是直接取出放入alistalist.append(sublist)for i in alist:if type(i) == type([]):#判断是否还有列表a =+ 1breakif a==1:return printlist(alist) #还有列表,进行递归if a==0:return alist#PCA降维def pca_analysis(data,n_components='mle'):index = data.indexmodel = PCA(n_components=n_components)model.fit(data)data_pca = model.transform(data)df = pd.DataFrame(data_pca,index=index)return df'''数据准备'''# 因子排列组合函数def factor_combins(data):''' 输入: 格式为Dataframe data 输出: 格式为list 所有因子的排列组合 '''# 排列组合factor_combins =[]for i in range(len(data.columns)+1):combins = [c for c in combinations((data.columns),i)]factor_combins.append(combins)# 剔除排列组合中空的情况factor_combins.pop(0)# 多层列表展开平铺成一层factor_list = list(itertools.chain(*factor_combins))return factor_list#获取时间为date的全部因子数据def get_factor_data(stock_list,date):data=pd.DataFrame(index=stock_list)# 第一波因子提取q = query(valuation,balance,cash_flow,income,indicator).filter(valuation.code.in_(stock_list))df = get_fundamentals(q, date)df['market_cap']=df['market_cap']*100000000df.index = df['code']del df['code'],df['id']# 第二波因子提取factor_data=get_factor_values(stock_list,['roe_ttm','roa_ttm','total_asset_turnover_rate',\ 'net_operate_cash_flow_ttm','net_profit_ttm',\ 'cash_to_current_liability','current_ratio',\ 'gross_income_ratio','non_recurring_gain_loss',\'operating_revenue_ttm','net_profit_growth_rate'],end_date=date,count=1)# 第二波因子转dataframe格式factor=pd.DataFrame(index=stock_list)for i in factor_data.keys():factor[i]=factor_data[i].iloc[0,:]#合并得大表df=pd.concat([df,factor],axis=1)# 有些因子没有的,用别的近似代替df.fillna(0, inplace = True)# profitability 因子# proft/net revenuedata['gross_profit_margin'] = df['gross_profit_margin']data['net_profit_margin'] = df['net_profit_margin']data['operating_profit_margin'] = df['operating_profit']/(df['total_operating_revenue']-df['total_operating_cost'])data['pretax_margin'] = (df['net_profit'] + df['income_tax_expense'])/(df['total_operating_revenue']-df['total_operating_cost'])# profit/capitaldata['ROA'] = df['roa']data['EBIT_OA'] = df['operating_profit']/df['total_assets']data['ROTC'] = df['operating_profit']/(df['total_owner_equities'] + df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])data['ROE'] = df['roe']# Othersdata['inc_total_revenue_annual'] = df['inc_total_revenue_annual']# Activity 因子# inve*rydata['inve*ry_turnover'] = df['operating_cost']/df['inve*ries']data['inve*ry_processing_period'] = 365/data['inve*ry_turnover']# account receivablesdata['receivables_turnover'] =df['total_operating_revenue']/df['account_receivable']data['receivables_collection_period'] = 365/data['receivables_turnover']# activity cycledata['operating_cycle'] = data['receivables_collection_period']+data['inve*ry_processing_period']# Other turnoversdata['total_asset_turnover'] = df['operating_revenue']/df['total_assets']data['fixed_assets_turnover'] = df['operating_revenue']/df['fixed_assets']data['working_capital_turnover'] = df['operating_revenue']/(df['total_current_assets']-df['total_current_liability'])# Liquidity 因子data['current_ratio'] =df['current_ratio']data['quick_ratio'] =(df['total_current_assets']-df['inve*ries'])/df['total_current_liability']data['cash_ratio'] = (df['cash_equivalents']+df['proxy_secu_proceeds'])/df['total_current_liability']# leverage data['debt_to_equity'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_owner_equities']data['debt_to_capital'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/(df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable']+df['total_owner_equities']) data['debt_to_assets'] = (df['longterm_loan'] + df['shortterm_loan']+df['borrowing_from_centralbank']+df['bonds_payable']+df['longterm_account_payable'])/df['total_assets']data['financial_leverage'] = df['total_assets'] / df['total_owner_equities']# Valuation 因子# Pricedata['EP']=df['net_profit_ttm']/df['market_cap']data['PB']=df['pb_ratio']data['PS']=df['ps_ratio']data['P/CF']=df['market_cap']/df['net_operate_cash_flow']# 技术面 因子# 下面技术因子来自于西交大元老师量化小组的SVM研究,report,https://www.joinquant.com/view/community/detail/15371stock = stock_list#个股60个月收益与上证综指回归的截距项与BETAstock_close=get_price(stock, count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']SZ_close=get_price('000001.XSHG', count = 60*20+1, end_date=date, frequency='daily', fields=['close'])['close']stock_pchg=stock_close.pct_change().iloc[1:]SZ_pchg=SZ_close.pct_change().iloc[1:]beta=[]stockalpha=[]for i in stock:temp_beta, temp_stockalpha = stats.linregress(SZ_pchg, stock_pchg[i])[:2]beta.append(temp_beta)stockalpha.append(temp_stockalpha)#此处alpha beta为listdata['alpha']=stockalphadata['beta']=beta#动量data['return_1m']=stock_close.iloc[-1]/stock_close.iloc[-20]-1data['return_3m']=stock_close.iloc[-1]/stock_close.iloc[-60]-1data['return_6m']=stock_close.iloc[-1]/stock_close.iloc[-120]-1data['return_12m']=stock_close.iloc[-1]/stock_close.iloc[-240]-1#取换手率数据data_turnover_ratio=pd.DataFrame()data_turnover_ratio['code']=stocktrade_days=list(get_trade_days(end_date=date, count=240*2))for i in trade_days:q = query(valuation.code,valuation.turnover_ratio).filter(valuation.code.in_(stock))temp = get_fundamentals(q, i)data_turnover_ratio=pd.merge(data_turnover_ratio, temp,how='left',on='code')data_turnover_ratio=data_turnover_ratio.rename(columns={'turnover_ratio':i})data_turnover_ratio=data_turnover_ratio.set_index('code').T #个股个股最近N个月内用每日换手率乘以每日收益率求算术平均值data['wgt_return_1m']=mean(stock_pchg.iloc[-20:]*data_turnover_ratio.iloc[-20:])data['wgt_return_3m']=mean(stock_pchg.iloc[-60:]*data_turnover_ratio.iloc[-60:])data['wgt_return_6m']=mean(stock_pchg.iloc[-120:]*data_turnover_ratio.iloc[-120:])data['wgt_return_12m']=mean(stock_pchg.iloc[-240:]*data_turnover_ratio.iloc[-240:])#个股个股最近N个月内用每日换手率乘以函数exp(-x_i/N/4)再乘以每日收益率求算术平均值temp_data=pd.DataFrame(index=data_turnover_ratio[-240:].index,columns=stock)temp=[]for i in range(240):if i/20<1:temp.append(exp(-i/1/4))elif i/20<3:temp.append(exp(-i/3/4))elif i/20<6:temp.append(exp(-i/6/4))elif i/20<12:temp.append(exp(-i/12/4)) temp.reverse()for i in stock:temp_data[i]=tempdata['exp_wgt_return_1m']=mean(stock_pchg.iloc[-20:]*temp_data.iloc[-20:]*data_turnover_ratio.iloc[-20:])data['exp_wgt_return_3m']=mean(stock_pchg.iloc[-60:]*temp_data.iloc[-60:]*data_turnover_ratio.iloc[-60:])data['exp_wgt_return_6m']=mean(stock_pchg.iloc[-120:]*temp_data.iloc[-120:]*data_turnover_ratio.iloc[-120:])data['exp_wgt_return_12m']=mean(stock_pchg.iloc[-240:]*temp_data.iloc[-240:]*data_turnover_ratio.iloc[-240:])#波动率data['std_1m']=stock_pchg.iloc[-20:].std()data['std_3m']=stock_pchg.iloc[-60:].std()data['std_6m']=stock_pchg.iloc[-120:].std()data['std_12m']=stock_pchg.iloc[-240:].std()#股价data['ln_price']=np.log(stock_close.iloc[-1])#换手率data['turn_1m']=mean(data_turnover_ratio.iloc[-20:])data['turn_3m']=mean(data_turnover_ratio.iloc[-60:])data['turn_6m']=mean(data_turnover_ratio.iloc[-120:])data['turn_12m']=mean(data_turnover_ratio.iloc[-240:])data['bias_turn_1m']=mean(data_turnover_ratio.iloc[-20:])/mean(data_turnover_ratio)-1data['bias_turn_3m']=mean(data_turnover_ratio.iloc[-60:])/mean(data_turnover_ratio)-1data['bias_turn_6m']=mean(data_turnover_ratio.iloc[-120:])/mean(data_turnover_ratio)-1data['bias_turn_12m']=mean(data_turnover_ratio.iloc[-240:])/mean(data_turnover_ratio)-1#技术指标data['PSY']=pd.Series(PSY(stock, date, timeperiod=20))data['RSI']=pd.Series(RSI(stock, date, N1=20))data['BIAS']=pd.Series(BIAS(stock,date, N1=20)[0])dif,dea,macd=MACD(stock, date, SHORT = 10, LONG = 30, MID = 15)data['DIF']=pd.Series(dif)data['DEA']=pd.Series(dea)data['MACD']=pd.Series(macd)# 去infa = np.array(data)where_are_inf = np.isinf(a)a[where_are_inf] = nanfactor_data =pd.DataFrame(a, index=data.index, columns = data.columns)return factor_data# 行业代码获取函数def get_industry(date,industry_old_code,industry_new_code):''' 输入: date: str, 时间点 industry_old_code: list, 旧的行业代码 industry_new_code: list, 新的行业代码 输出: list, 行业代码 ''' #获取行业因子数据if datetime.datetime.strptime(date,"%Y-%m-%d").date()<datetime.date(2014,2,21):industry_code=industry_old_codeelse:industry_code=industry_new_codelen(industry_code)return industry_code#取股票对应行业def get_industry_name(i_Constituent_Stocks, value):return [k for k, v in i_Constituent_Stocks.items() if value in v]#缺失值处理def replace_nan_indu(factor_data, stockList, industry_code, date): ''' 输入: factor_data: dataframe, 有缺失值的因子值 stockList: list, 指数池子所有标的 industry_code: list, 行业代码 date: str, 时间点 输出: 格式为list 所有因子的排列组合 ''' # 创建一个字典,用于储存每个行业对应的成分股(行业标的和指数标的取交集)i_Constituent_Stocks={}# 创建一个行业因子数据表格,待填因子数据(暂定为均值)ind_factor_data = pd.DataFrame(index=industry_code,columns=factor_data.columns)# 遍历所有行业for i in industry_code:# 获取单个行业所有的标的stk_code = get_industry_stocks(i, date) # 储存每个行业对应的所有成分股到刚刚创建的字典中(行业标的和指数标的取交集)i_Constituent_Stocks[i] = list(set(stk_code).intersection(set(stockList)))# 对于某个行业,根据提取出来的指数池子,把所有交集内的因子值取mean,赋值到行业因子值的表格上ind_factor_data.loc[i]=mean(factor_data.loc[i_Constituent_Stocks[i],:])# 对于行业值缺失的(行业标的和指数标的取交集),用所有行业的均值代替for factor in ind_factor_data.columns:# 提取行业缺失值所在的行业,并放到list去null_industry=list(ind_factor_data.loc[pd.isnull(ind_factor_data[factor]),factor].keys())# 遍历行业缺失值所在的行业for i in null_industry:# 所有行业的均值代替,行业缺失的数值ind_factor_data.loc[i,factor]=mean(ind_factor_data[factor])# 提取含缺失值的标的null_stock=list(factor_data.loc[pd.isnull(factor_data[factor]),factor].keys())# 用行业值(暂定均值)去填补,指数因子缺失值for i in null_stock:industry = get_industry_name(i_Constituent_Stocks, i)if industry:factor_data.loc[i, factor] = ind_factor_data.loc[industry[0], factor]else:factor_data.loc[i, factor] = mean(factor_data[factor])return factor_data#去除上市距beginDate不足1年且退市在endDate之后的股票def delect_stop(stocks,beginDate,endDate,n=365):stockList=[]beginDate = datetime.datetime.strptime(beginDate, "%Y-%m-%d")endDate = datetime.datetime.strptime(endDate, "%Y-%m-%d")for stock in stocks:start_date=get_security_info(stock).start_dateend_date=get_security_info(stock).end_dateif start_date<(beginDate-datetime.timedelta(days=n)).date() and end_date>endDate.date():stockList.append(stock)return stockList# 获取预处理后的因子(不含PCA降维)def prepare_data(date,index):''' 输入: date: str, 时间点 index: 指数 输出: data: 预备处理好的了dataframe '''
# 指数池子提取stockList = get_index_stocks(index , date=date)#剔除ST股st_data=get_extras('is_st',stockList, count = 1,end_date = start_date)stockList = [stock for stock in stockList if not st_data[stock][0]]#剔除停牌、新股及退市股票stockList=delect_stop(stockList,date,date)# 获取数据factor_data = get_factor_data(stockList, date)# 数据预处理# 缺失值处理data = replace_nan_indu(factor_data, stockList, industry_code, date)# 启动内置函数去极值data = winsorize(data, qrange=[0.05,0.93], inclusive=True, inf2nan=True, axis=0)# 启动内置函数标准化data = standardlize(data, inf2nan=True, axis=0)# 启动内置函数中性化,行业为'sw_l1'data = neutralize(data, how=['sw_l1','market_cap'], date=date , axis=0)return data'''时间准备'''# 时间管理函数def time_handle(start_date, end_date, period, period_pre,index):''' 输入: start_date: 开始时间,str end_date: 截至时间,str period: 周期间隔,str(转换为周是'W',月'M',季度线'Q',五分钟'5min',12天'12D') period_pre: 小周期间隔,str(为了提取第一个T0数据,作为辅助用途) 输出: 格式为dataframe columns: T0: T0时间点的集合 T1: T1时间点的集合 T2: T2时间点的集合 '''# 设定转换周期 period_type 转换为周是'W',月'M',季度线'Q',五分钟'5min',12天'12D'time = get_price(index ,start_date,end_date,'daily',fields=['close'])# 记录每个周期中最后一个交易日time['date']=time.index# 进行转换,周线的每个变量都等于那一周中最后一个交易日的变量值period_handle=time.resample(period,how='last')period_handle['t1'] = period_handle['date']# 创造超前数据T2period_handle['t2']=period_handle['t1'].shift(-1)# 重新设定index,设为模型运行次数period_handle.index = range(len(period_handle))# 构建T0period_handle['t0'] = period_handle['t1'].shift(1)# 重新获取小一个周期的数据time1 = get_price(index ,start_date, end_date,'daily',fields=['close'])# 记录每个周期中最后一个交易日time1['date']=time1.index# 进行转换,周线的每个变量都等于那一周中最后一个交易日的变量值ph =time1.resample(period_pre,how='last').dropna()# 通过更小的周期来提取的最后一个交易日的值,来提取大表格的第一个T0period_handle['t0'][0] = ph['date'][0]# 记录模型运行次数period_handle['Replication#'] = period_handle.indexperiod_handle['Replication'] = period_handle['Replication#'].shift(-1)del period_handle['Replication#']del period_handle['date']# 重新排列列表顺序period_handle['T0'] = period_handle['t0']period_handle['T1'] = period_handle['t1']period_handle['T2'] = period_handle['t2']del period_handle['close']del period_handle['t0']del period_handle['t1']del period_handle['t2']period_handle.to_csv('period_handle.csv')return period_handle# 时间格式修改(从timestamp改为str)def time_fix(period_handle):# 导入时间周期管理函数p = time_handle(start_date, end_date, period, period_pre,index)# dropna 并且list化datelist_T0 = list(p.dropna()['T0'])datelist_T1 = list(p.dropna()['T1'])datelist_T2 = list(p.dropna()['T2'])# timestamp 转strdatelist_T0 = list(np.vectorize(lambda s: s.strftime('%Y-%m-%d'))(datelist_T0))datelist_T1 = list(np.vectorize(lambda s: s.strftime("%Y-%m-%d"))(datelist_T1))datelist_T2 = list(np.vectorize(lambda s: s.strftime("%Y-%m-%d"))(datelist_T2))# list字典化,并转为dateframet = {'T0': datelist_T0, 'T1':datelist_T1, 'T2':datelist_T2}test_timing = pd.DataFrame(t)return test_timing '''分类函数'''# 获取指数在所有周期内的池子,然后取不重复set的并集,变成新的池子def get_all_index_stock(index, period_handle):''' 输入: stock_list: 所有周期池子的出现过的股票, list period_handle: 周期管理函数出来的时间集合, dataframe 输出: stock_list: list, 所有周期内,于指数出现过的标的池子 '''# 时间周期管理p = time_handle(start_date, end_date, period, period_pre,index)# 大池子提取stock_list_pre = []for date in p['T0']:# 获取每个T0的指数池子stk_list = get_index_stocks(index , date=date)# 放到stock_list里面stock_list_pre.append(stk_list)# *多重列表,去重复,返回lists = splitlist(stock_list_pre)stock_list = list(set(s))
return stock_list# 所有周期,指数池子里面所有股票的周期收益率def get_index_big_pool_return(stock_list, period_handle):''' 输入: stock_list: 所有周期池子的出现过的股票, list period_handle: 周期管理函数出来的时间集合, dataframe 输出: 格式为dataframe columns: T0: T0时间点的集合 code1: 标的1在T0到T1的收益率 code2: 标的2在T0到T1的收益率 以此类推 '''# 获取指数池子所有的索引stock_code = stock_listp = time_handle(start_date, end_date, period, period_pre,index)# 获取时间表格,剔除T1、T2和Replication列stk_return = p.copy()# 收益率计算for j in stock_code:j_str = str(j)p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,1]]p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]a = [(m-n)/n for m,n in zip (p1,p0)]stk_return[str(j)] = a# 删除T1列,保留T0列 ,并赋值给index del stk_return['T1']stk_return.index = stk_return['T0']del stk_return['T0']del stk_return['T2']del stk_return['Replication']# 缺失值用0填补stk_return.fillna(0)# 保存stk_return.to_csv('stock_return.csv')return stk_return# 训练:分类函数def train_classification(stk_return, index_return):''' 输入: skt_retun: 所有标的在T0-T1时间集当中的周期收益率, dataframe index_return: 指数在T0-T1时间集合中的周期收益率, dataframe 输出: 格式为dataframe columns: T0: T0时间点的集合 index: code1: 在T0-T1这个周期里面是否跑赢大盘,跑赢为'1',否则为'0' code2: 是否跑赢大盘,分类数据 以此类推 '''# 复制skt_return的dataframe为最终的输出格式stock_cl = stk_return.copy()# 遍历比较,赋值for j in range(len(stock_cl.index)):for i in range(len(stock_cl.columns)):if stock_cl.iloc[j,i] > index_return.iloc[j,0]: stock_cl.iloc[j,i] = 1else:stock_cl.iloc[j,i] = 0# 转置stock_cl = stock_cl.T# 保存stock_cl.to_csv('stock_classification_data.csv') return stock_cl# 获取T0 到 T1时间段,指数周期收益率def get_index_return_train(index,period_handle):''' 输入: index: 指数, 元素str period_handle: 周期管理函数出来的时间集合, dataframe 输出: 格式为dataframe columns: T0: T0时间点的集合 index_return: 指数在T0到T1的收益率 '''# 获取时间表格,剔除T1、T2和Replication列p = time_handle(start_date, end_date, period, period_pre,index)index_return = p.copy()del index_return['Replication']del index_return['T2']# 收益率计算 p0 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,1]]p1 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,2]]a = [(m-n)/n for m,n in zip(p1,p0) ]index_return['index_return'] = adel index_return['T1']index_return.index = index_return['T0']del index_return['T0']# 保存现成的表格index_return.to_csv('index_return.csv')return index_return# 获取T1 到 T2 时间段, 指数周期的收益率def get_index_return_test(index,period_handle):''' 输入: index: 指数, 元素str period_handle: 周期管理函数出来的时间集合, dataframe 输出: 格式为dataframe columns: T2: T2时间点的集合 index_return: 指数在T0到T1的收益率 '''# 获取时间表格,剔除T1、T2和Replication列p = time_handle(start_date, end_date, period, period_pre,index).dropna()index_return = p.copy()del index_return['Replication']del index_return['T0']# 收益率计算 p0 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,2]]p1 = [float(get_price(index,i,i)['close']) for i in p.iloc[:,3]]a = [(m-n)/n for m,n in zip(p1,p0) ]index_return['index_return'] = adel index_return['T1']index_return.index = index_return['T2']del index_return['T2']# 保存现成的表格index_return.to_csv('index_return.csv')return index_return# 获取T0 到 T1时间段,指数池子里面所有股票的周期收益率def get_stock_return_train(data, period_handle):''' 输入: data: 因子提取的大表格, dataframe period_handle: 周期管理函数出来的时间集合, dataframe 输出: 格式为dataframe columns: T0: T0时间点的集合 code1: 标的1在T0到T1的收益率 code2: 标的2在T0到T1的收益率 以此类推 '''# 获取指数池子所有的索引stock_code = list(data.index)p = time_handle(start_date, end_date, period, period_pre,index)# 获取时间表格,剔除T1、T2和Replication列stk_return = p.copy()# 收益率计算for j in stock_code:j_str = str(j)p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,1]]p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]a = [(m-n)/n for m,n in zip (p1,p0)]stk_return[str(j)] = a# 删除T1列,保留T0列 ,并赋值给index del stk_return['T1']stk_return.index = stk_return['T0']del stk_return['T0']del stk_return['T2']del stk_return['Replication']# 保存文件stk_return.to_csv('stk_return_train.csv')return stk_return# 获取 T1 到 T2时间段,预测池子里面所有股票的周其收益率def get_stock_return_test(pool_list, period_handle):''' 输入: pool_list: 根据预测出来的标的池子, list period_handle: 周期管理函数出来的时间集合, dataframe 输出: 格式为dataframe columns: T2时间点集合 index: 股票对应的收益率 '''p = time_handle(start_date, end_date, period, period_pre,index)# 获取时间表格,剔除T1、T2和Replication列stk_return = p.copy()# 收益率计算for j in pool_list:j_str = str(j)p0 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,2]]p1 = [float(get_price(j,i,i)['close'])for i in p.iloc[:,3]]a = [(m-n)/n for m,n in zip (p1,p0)]stk_return[str(j)] = a# 删除T1列,保留T0列 ,并赋值给index del stk_return['T1']stk_return.index = stk_return['T0']del stk_return['T0']del stk_return['T2']del stk_return['Replication']# 保存文件stk_return.to_csv('stk_return_train.csv')return stk_return'''训练和回测准备'''# 根据预测并提取预测池子函数def model_pool(stock_cl, num, clf, clf1, test_timing):''' 输入: stock_cl: 用以训练的分类数据 num = 第几次 clf: 模型 test_timing: str化的时间周期 输出: pool_list: 根据模型出来的股票池子 '''# 获取T0时间点的因子数据data = prepare_data(test_timing['T0'][num], index)# 获取T1时间点的因子数据data_test = prepare_data(test_timing['T1'][num],index)# 如果 T0 和 T1 两个时间点出来的因子数据,因为某标的剔除导致index不匹配if len(data.index) != len(data_test.index):# 取交集作为分类值,训练还有预测值data_adj = data.loc[data.index & data_test.index,:] data_test_adj = data_test.loc[data.index & data_test.index,:]stock_cl_adj = stock_cl.loc[data.index & data_test.index,:]# 训练X_train = np.array(data_adj)Y_train = np.array(stock_cl_adj.T)[num]# 算法训练clf.fit(X_train, Y_train)# 预测X_predict = np.array(data_test_adj) # 根据T0到T1的训练模型,基于T1的因子数据,做T1-T2的分类结果预测Y_predict = clf.predict(X_predict) # 如果用第一种算法预测结果都为0,用第二种算法fit一次if all (Y_predict == 0):# 算法训练第二次clf1.fit(X_train, Y_train)# 预测第二遍X_predict = np.array(data_test) Y_predict = clf1.predict(X_predict)# 如果匹配则,按照原计划进行else: X_train = np.array(data)stock_cl_adj = stock_cl.loc[data.index,:]Y_train = np.array(stock_cl_adj.T)[num]# 算法训练clf.fit(X_train, Y_train)
# 预测data_test_adj = data_test.copy()X_predict = np.array(data_test_adj) # 根据T0到T1的训练模型,基于T1的因子数据,做T1-T2的分类结果预测Y_predict = clf.predict(X_predict)# 如果用第一种算法预测结果都为0,用第二种算法fit一次if all (Y_predict == 0):# 算法训练第二次clf1.fit(X_train, Y_train)# 预测第二遍X_predict = np.array(data_test_adj) Y_predict = clf1.predict(X_predict)# 构建在T1预测T2的分类表格s = {'predict_clf': list(Y_predict)}s = pd.DataFrame(s)s.index = data_test_adj.index# 获取预测池子的平均收益率model_predict = []pool_list = []# 提取预测的分类值为1的标的for a in range(len(s)): if s.iloc[a,0] == 1:# 捕捉分类为1的index,添加到信的list中pool_list.append(str(s.index[a]))return pool_list# 根据模型筛选的股票池子出来的平均收益率def get_model_return(pool_list, test_timing,num):''' 输入: pool_list: 筛选出来的股票池子 test_timing: 周期函数 输出: model_mean_return: 预测出来标的的平均收益率 '''return_test_list = []for j in pool_list:j_str = str(j)datelist_T1 = test_timing['T1']datelist_T2 = test_timing['T2']p1 = [float(get_price(j, datelist_T1[num],datelist_T1[num])['close'])]p2 = [float(get_price(j, datelist_T2[num],datelist_T2[num])['close'])]a = [(m-n)/n for m,n in zip (p2,p1)]# 捕捉分类为1的index,添加到信的list中return_test_list.append(a[0])stk_test = {'pool_list':pool_list, 'return_test_list':return_test_list}stk_test = pd.DataFrame(stk_test)stk_test.index = stk_test['pool_list']del stk_test['pool_list']# 收益率获取model_mean_return = stk_test.mean()return model_mean_return# 将预测出来的股票池子转化为dataframe格式def predict_pool(pool_list):# 字典化为dataframepredict_pool ={'predict_pool':pool_list, 'predict_score':1}predict_pool = pd.DataFrame(predict_pool)predict_pool.index = predict_pool['predict_pool']del predict_pool['predict_pool']return predict_pool # 实际分类池子函数def actural_pool(act_cl, test_timing):''' 输入: act_cl: 分类池子 test_timing: str化的时间周期 输出: 格式为dataframe 实际分类池子 '''# 提取真实的分类数据act_c = act_cl.copy()del act_c[(act_c.columns)[0]]act_c.columns = test_timing['T2']actural_cl = act_c[act_c.columns[num]]# 字典化为dataframeactural_pool = {'act_pool':actural_cl.index, 'act_score':(actural_cl)}actural_pool = pd.DataFrame(actural_pool)del actural_pool['act_pool']return actural_pool# 大模型测试函数# 自动化生成对比收益率函数def test_return(start_date, end_date, period, period_pre, index, clf, clf1):''' 输入: index: 指数 clf: 模型 输出: 格式为dataframe index: T2时间节点 index_return: 大盘在T1-T2的收益 model_return: 模型在T1-T2的收益 pool_number: 模型在T1-T2预测池子数量 '''# 获取时间周期p = time_handle(start_date, end_date, period, period_pre,index)test_timing = time_fix(p)# 辅助data = prepare_data(start_date,index)# 获取 T0 到 T1 时间段,指数池子里面所有股票的周期收益率stk_return = get_stock_return_train(data,p)# 获取 T0 到 T1 时间段,指数周期收益率index_return = get_index_return_train(index,p)# 获取用来训练的分类数据stock_cl = train_classification(stk_return, index_return)# 回测分类,实际的分类情况获取act_cl = actural_classification(p, stock_cl)# 剔除最后一列(因为p的最后一行的T2是nan值)del stock_cl[stock_cl.columns[-1]]# 获取T1 到 T2 时间段, 指数周期的收益率index_return_test = get_index_return_test(index,p)# 模型收益率提取predict_return = []# 每一次预测池子标的数量提取pool_num = []for num in range(len(test_timing['T0'])):print('正在进行第'+str(num+1)+'次训练、预测')# 获取预测的poolpool = model_pool(stock_cl,num,clf, clf1, test_timing)# 根据预测的pool获取周期均收益率model_mean_return = get_model_return(pool, test_timing, num)# 把均收益率放到predict_return这个list中predict_return.append(model_mean_return)# 记录预测池子数量pool_num.append(len(pool))# 对比预测池子周期均收益率和大盘周期均收益率compare = index_return_test.copy()cp_return = pd.DataFrame(predict_return)cp_return.index = compare.indexcp_return['index_return'] = compare['index_return']cp_return['model_return'] = cp_return['return_test_list']del cp_return['return_test_list']cp_return['premium'] = cp_return['model_return'] - cp_return['index_return']# 记录预测池子数量cp_return['pool_number'] = pool_numprint('所有周期数据训练、预测已经完成')return cp_return # 结果可视化def visualization(df):''' 输入: df: 自动化生成对比收益率表格 输出: 可视化结果 '''del df['pool_number']
df.columns = ['指数大盘收益率','模型收益率','模型超额收益率']df.plot(figsize=(15,8),title= "模型收益率(折线图)")df.plot.bar(figsize=(15,8),title= "模型收益率(柱状图)")# 跑赢or输结果# 记录对比大盘结果的次数count1 = []for j in range(len(df)):if df.iloc[j,2] < 0:count1.append(j)count2 = []for j in range(len(df)):if df.iloc[j,2] > 0:count2.append(j)
return df.plot(figsize=(15,8),title= "模型收益率(折线图)"), df.plot.bar(figsize=(15,8),title= "模型收益率(柱状图)"), '总回测次数:', len(df), '跑输的次数:', len(count1), '跑赢的次数:', len(count2)# 参数准备 import timestart = time.clock()# 参数 date = '2014-01-01'start_date ='2014-01-01'end_date = '2019-03-01'period = 'M'period_pre = 'D'S = '399905.XSHE'index = S# 行业:申万一级industry_old_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\'801160','801170','801180','801200','801210','801230']industry_new_code = ['801010','801020','801030','801040','801050','801080','801110','801120','801130','801140','801150',\'801160','801170','801180','801200','801210','801230','801710','801720','801730','801740','801750',\ '801760','801770','801780','801790','801880','801890']# 行业获取industry_code = get_industry(date,industry_old_code,industry_new_code)from sklearn.neural_network import MLPClassifier# 算法模型# 算法一clf = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5, 2), random_state=1)# 辅助算法二,用于预测值都为0的状况regressor = svm.SVC()# SVM算法参数设计parameters = {'kernel':['rbf'],'C':[0.01,0.03,0.1,0.3,1,3,10],\ 'gamma':[1e-4,3e-4,1e-3,3e-3,0.01,0.03,0.1,0.3,1]}# 创建网格搜索 scoring:指定多个评估指标 cv: N折交叉验证clf1 = GridSearchCV(regressor,parameters,cv=10)# 各种准备# 获取时间周期print('时间周期获取中……')p = time_handle(start_date, end_date, period, period_pre,index)test_timing = time_fix(p)# 辅助因子表格print('辅助因子表格获取中……')data = prepare_data(date,index)# 获取指数周期收益率print('指数周期收益率获取中……')index_return = get_index_return_train(S,p)# 获取中证500在所有周期内的池子,然后取不重复set的交集,变成新的池子print('分类表格获取中……')stock_list = get_all_index_stock(index, p)# 获取该池子的stk_returnstk_return = get_index_big_pool_return(stock_list,p)# 获取所有周期所有指数池子在所有周期的分类值stock_cl = train_classification(stk_return, index_return)# 剔除最后一列(因为T2是nan值)del stock_cl[stock_cl.columns[-1]]# 获取T1-T2指数收益率数据,用以测试print('T1-T2收益率表格获取中……')index_return_test = get_index_return_test(index,p)elapsed = (time.clock()- start)print('所有准备工作完成!')print('所用时间:', elapsed)时间周期获取中…… 辅助因子表格获取中…… 指数周期收益率获取中…… 分类表格获取中…… T1-T2收益率表格获取中…… 所有准备工作完成! 所用时间: 301.700737
# 模型收益率提取import timestart = time.clock()predict_return = []# 每一次预测池子标的数量提取pool_num = []for num in range(len(test_timing['T0'])):print('正在进行第'+str(num+1)+'次训练、预测……')# 获取预测的poolpool = model_pool(stock_cl,num,clf, clf1, test_timing)# 根据预测的pool获取周期均收益率model_mean_return = get_model_return(pool, test_timing, num)# 把均收益率放到predict_return这个list中predict_return.append(model_mean_return)# 记录预测池子数量pool_num.append(len(pool))# 对比预测池子周期均收益率和大盘周期均收益率compare = index_return_test.copy()cp_return = pd.DataFrame(predict_return)cp_return.index = compare.indexcp_return['index_return'] = compare['index_return']cp_return['model_return'] = cp_return['return_test_list']del cp_return['return_test_list']cp_return['premium'] = cp_return['model_return'] - cp_return['index_return']# 记录预测池子数量cp_return['pool_number'] = pool_numprint('所有周期数据训练、预测已经完成,周期数量为'+str(num+1))elapsed = (time.clock()- start)print('所用时间:', elapsed)# 保存cp_return.to_csv('model_return.csv')正在进行第1次训练、预测…… 正在进行第2次训练、预测…… 正在进行第3次训练、预测…… 正在进行第4次训练、预测…… 正在进行第5次训练、预测…… 正在进行第6次训练、预测…… 正在进行第7次训练、预测…… 正在进行第8次训练、预测…… 正在进行第9次训练、预测…… 正在进行第10次训练、预测…… 正在进行第11次训练、预测…… 正在进行第12次训练、预测…… 正在进行第13次训练、预测…… 正在进行第14次训练、预测…… 正在进行第15次训练、预测…… 正在进行第16次训练、预测…… 正在进行第17次训练、预测…… 正在进行第18次训练、预测…… 正在进行第19次训练、预测…… 正在进行第20次训练、预测…… 正在进行第21次训练、预测…… 正在进行第22次训练、预测…… 正在进行第23次训练、预测…… 正在进行第24次训练、预测…… 正在进行第25次训练、预测…… 正在进行第26次训练、预测…… 正在进行第27次训练、预测…… 正在进行第28次训练、预测…… 正在进行第29次训练、预测…… 正在进行第30次训练、预测…… 正在进行第31次训练、预测…… 正在进行第32次训练、预测…… 正在进行第33次训练、预测…… 正在进行第34次训练、预测…… 正在进行第35次训练、预测…… 正在进行第36次训练、预测…… 正在进行第37次训练、预测…… 正在进行第38次训练、预测…… 正在进行第39次训练、预测…… 正在进行第40次训练、预测…… 正在进行第41次训练、预测…… 正在进行第42次训练、预测…… 正在进行第43次训练、预测…… 正在进行第44次训练、预测…… 正在进行第45次训练、预测…… 正在进行第46次训练、预测…… 正在进行第47次训练、预测…… 正在进行第48次训练、预测…… 正在进行第49次训练、预测…… 正在进行第50次训练、预测…… 正在进行第51次训练、预测…… 正在进行第52次训练、预测…… 正在进行第53次训练、预测…… 正在进行第54次训练、预测…… 正在进行第55次训练、预测…… 正在进行第56次训练、预测…… 正在进行第57次训练、预测…… 正在进行第58次训练、预测…… 正在进行第59次训练、预测…… 正在进行第60次训练、预测…… 正在进行第61次训练、预测…… 正在进行第62次训练、预测…… 所有周期数据训练、预测已经完成,周期数量为62 所用时间: 3589.145413
cp_return = pd.read_csv('model_return.csv')cp_return.index = cp_return['T2']del cp_return['T2']# 模型收益率表头cp_return.columns = ['指数大盘收益率','模型收益率','模型超额收益率','预测池子的数量']cp_return.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| 指数大盘收益率 | 模型收益率 | 模型超额收益率 | 预测池子的数量 | |
|---|---|---|---|---|
| T2 | ||||
| 2014-02-28 | 0.023295 | 0.034123 | 0.010828 | 203 |
| 2014-03-31 | -0.034052 | -0.029552 | 0.004501 | 220 |
| 2014-04-30 | -0.019364 | -0.015910 | 0.003454 | 296 |
| 2014-05-30 | 0.016746 | 0.023714 | 0.006968 | 281 |
| 2014-06-30 | 0.024981 | 0.028149 | 0.003167 | 246 |
# 可视化d = cp_return['预测池子的数量']d.plot(figsize=(15,8),title= "预测池子数量(折线图)")df = cp_return.copy()del df['预测池子的数量']df.columns = ['指数大盘收益率','模型收益率','模型超额收益率']df.plot(figsize=(15,8),title= "模型收益率(折线图)")df.plot.bar(figsize=(15,8),title= "模型收益率(柱状图)")
<matplotlib.axes._subplots.AxesSubplot at 0x7f49cde268d0>
# 记录跑赢次数count1 = []for j in range(len(df)):if df.iloc[j,2] < 0:count1.append(j)count2 = []for j in range(len(df)):if df.iloc[j,2] > 0:count2.append(j) print('总回测次数:', len(df), '跑输的次数:', len(count1), '跑赢的次数:', len(count2))print('胜率:', len(count2)/len(df))总回测次数: 62 跑输的次数: 18 跑赢的次数: 44 胜率: 0.7096774193548387
print('总周期数:'+str(len(cp_return)))print('模型累计收益率:',cp_return['模型收益率'].sum())print('指数累计收益率:',cp_return['指数大盘收益率'].sum())print('模型超额收益率:',cp_return['模型超额收益率'].sum())总周期数:62 模型累计收益率: 0.6611770810052777 指数累计收益率: 0.4755694386526886 模型超额收益率: 0.18560764235258892
# 累计收益率可视化import matplotlib.pyplot as pltdf = pd.DataFrame(index= cp_return.index)df['模型累计收益率'] = cp_return['模型收益率'].cumsum()df['指数累计大盘收益率'] = cp_return['指数大盘收益率'].cumsum()index_list =[]for i in df.index:i = datetime.datetime.strptime(i,'%Y-%m-%d')index_list.append(i)df.index = index_listdf.plot(figsize=(16,8))
<matplotlib.axes._subplots.AxesSubplot at 0x7f49c2c7ed68>
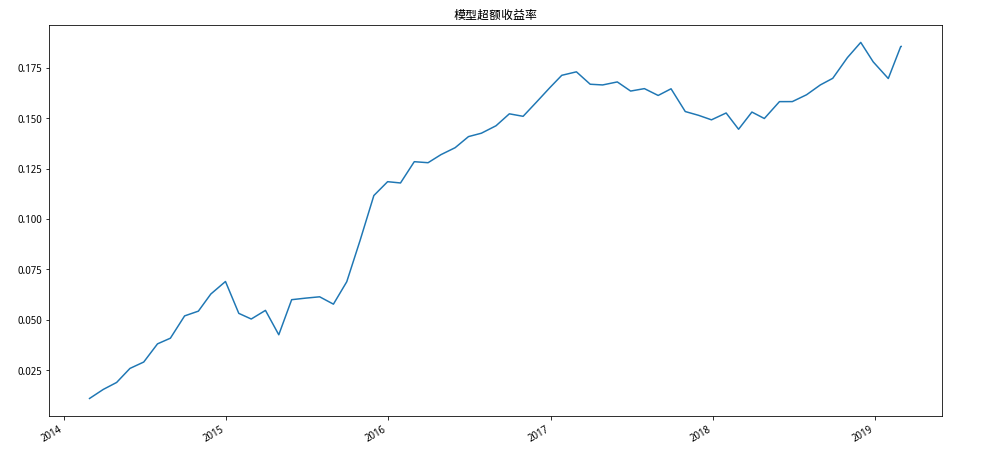
# 模型超额累进收益率df['模型超额收益率'] = cp_return['模型超额收益率']df['模型超额收益率'].cumsum().plot(figsize=(16,8),title= "模型超额收益率")
<matplotlib.axes._subplots.AxesSubplot at 0x7f49ca2*ef0>
下面是我总结出来对于模型的一些局限性和下次改进的ideas:
(1) 因子提取(筛选or降维):仅仅提取了公司的,没有提取宏观的甚至是行业的数据,下次我看看怎么弄;对于因子筛选(features selection), 我后期会开始做,两个逻辑:一个是统计逻辑,算出每个因子的IC,利用IC的各种指标等统计方法进行因子筛选;另一个逻辑是,套用半监督学习or无监督学习算法,让机器自己筛选因子or降维。
(2) 模型局限:周期之间训练出来的模型保持孤立状态,而且每一次预测完会有预测分类结果和实际分类结果(实际的结果我还没用到模型上), 如何对它们做cost function,甚至利用这个cost function对以后的周期训练作指导,这个问题我想了一下,可能需要套用各种RNN。
(3) 泛化误差:这个机器学习都会遇到的大问题,如何解决?在训练的过程中加入正则化函数?那么超参数又怎么去调整?这一块小弟才疏学浅还没弄懂。
欢迎各种Q,能解答的我都会答,多多交流,能加我微信聊就最好了哈哈

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程