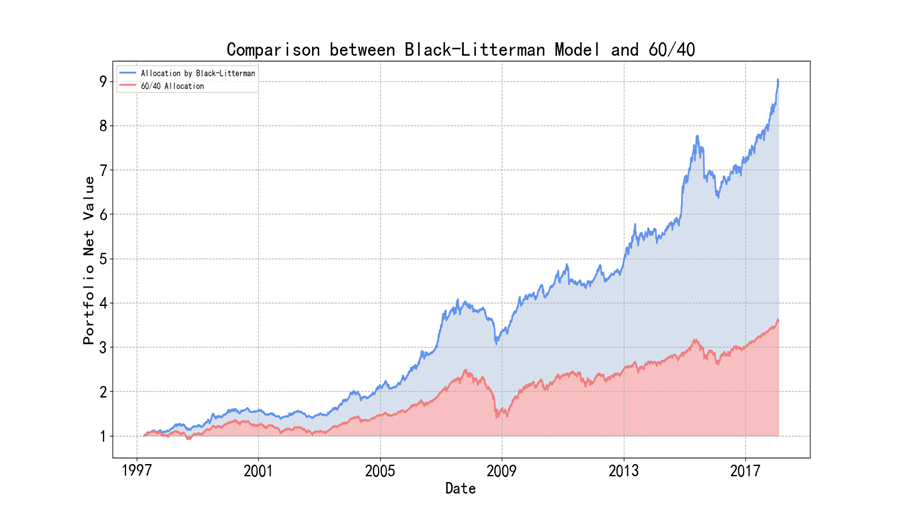
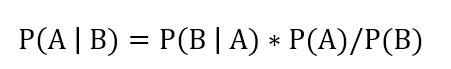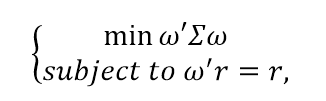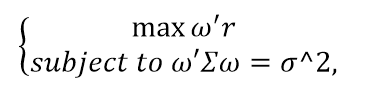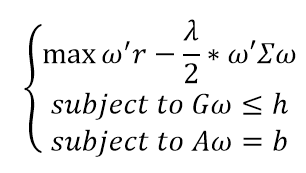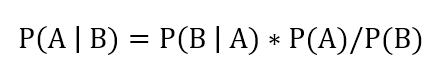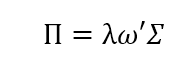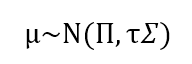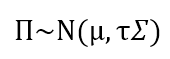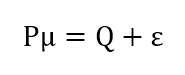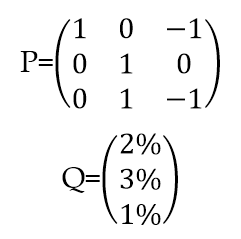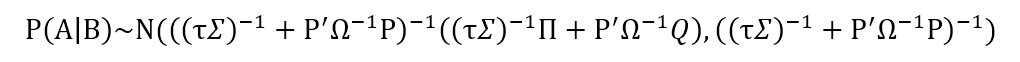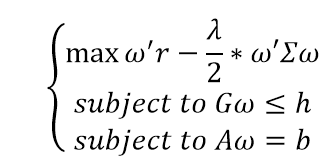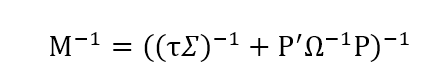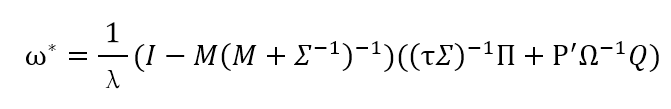在二级市场中,资产配置是永恒的主题。如何在各类资产之间合理的分配权重以在攫取更多收益的同时足够地防范风险,是二级市场投资首要解决的目标。本帖中,笔者将利用Goldman Sachs的Fischer Black和Robert Litterman于1990年提出的Black-Litterman大类资产配置模型,选取十个大类资产标的,沿用历史上从1997年至2018年间逾30年的投资区间,将Black-Litterman资产配置模型代码实现并进行回测。回测结果表明,应用Black-Litterman模型后,投资组合的表现大为改善。模型获得了12.31%的年化收益(对比标普500年均收益6%),最大回撤约20%(对比标普500最大回撤逾30%)。
选取十个大类资产(股权类6个,债权类4个),仅仅利用资产配置优化,增加收益,减少波动。
股权类:标普500指数(S&P 500)、摩根斯坦利新兴市场指数(MSCI EU)、日经指数(TOPIX)、沪深300指数(CSI 300)、摩根斯坦利亚洲除日本指数(MSCI APAC ex Japan)、摩根斯坦利新兴市场指数(MSCI Emerging Markets)
债权类:彭博-巴克莱全球混合指数(BB Global Aggregate, 对标投资级债券市场),美银美林美国高收益债券(BAML US High Yield, 对标垃圾债券),摩根大通政府债券指数(JPM Government Bond, 对标美国国债),摩根大通全球新兴市场债券指数(JPM Emerging Market Bond Index Global Diversified)
所有的标的均为上述指数对应的ETF
为了理解模型,需要首先理解贝叶斯原理:
在贝叶斯理论体系中,提到了先验和后验。我用一个故事来论述它的原理。
有一种病,在人群中,得了病的人,检测出阳性的概率为90%,阴性为10%。在人群中,得病的概率为1%。现在小明被检测出了阳性。
猛地一看,小明应该有很大几率得病了。但是贝叶斯说:不!
为什么?在人群中,得了病,并且是阳性的概率为:
90%×1%=0.9%
但是别忘了另外一种情况:没有得病,但是却被检测出来是阳性的概率是多少?别忘了,在现实中可能有误诊、检测手段不严格等问题,确实会导致【没有病但是是阳性】
10%×99%=9.9%
也就是说,小明现在得病的概率是:
(0.9%)/(0.9% 9.9%)=0.083
非常小的一个数。这也是贝叶斯的魅力所在。在上面的故事中,小明已经检测出阳性。我们要关注他是否得病,这个概率是后验概率,因为我们已经知道他检测出阳性了。而另外一个普通人,没有检测的时候,关注他是否得病,这个概率是先验概率,因为我们什么信息都没有。
明白了以上的原理,我们可以将其应用于量化投资。贝叶斯原理的基本公式是:
令A:市场观点;B:投资者观点;B | A:投资者基于市场观点下自己的观点;A | B:基于投资者观点的预期收益。这就是说,我们要在以前历史的市场收益信息下,获得投资者对于未来的预期收益。这也是一种先后验的问题。利用贝叶斯公式,可以求得基于投资者观点的预期收益的分布,也即P(A | B)。然后求得最优资产配置。
接下来,我们说一下最优规划问题。
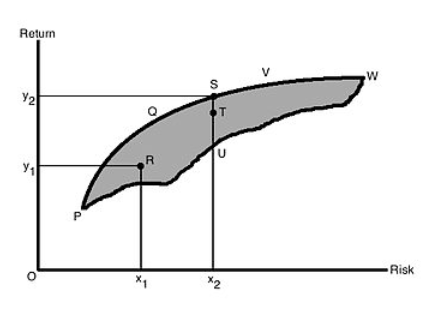
传统的Markowitz动态模型基于历史收益和波动完成,其缺点是模型对于参数太敏感。如下图:
事实上1%的收益改变能够大幅改变Markowitz中的仓位占比,从而显著影响收益,这不是一个良好、稳定的模型应有的性质。
Black-Litterman模型最大的优点在于,基于Black-Litterman模型加入了主观观点矩阵与贝叶斯先后验法则。该模型先根据CAPM下均衡市场的投资组合作为先验信息,结合投资者自身的观点,并将先验信息通过Bayesian法则转换为后验信息从而得到最终的资产配置。模型的核心假设在于,投资者以及其他人对于各类资产的观点、自己的信心、风险承受能力不同。最后得到的结果是已经融合预期的隐含的均衡预期收益以及最终权重。
给定各类资产的历史收益率,可以得到波动率等数据。基于历史收益与波动率,可以利用凸优化解出市场的先验均衡配置。注意,在应用这一方法的时候,我们仅仅考虑了历史数据,属于先验分布,对于未来是否具有强有力的预测能力未知。一般说来,解出以下线性规划可以得出先验均衡配置:
注:给定收益下最小化波动率
或者:
注:给定波动率下最大化收益
或者:
注:给定投资者的风险厌恶系数,计算出风险溢价。在满足多项关于资产配置约束的解的条件下,最大化扣除风险溢价后的收益*
上式中,ω为待求解的资产配置,r为历史收益率,Σ为各类资产相关性矩阵。
利用python的cvxopt包的solvers, matrix两个模块可以完成以上方程的求解,具体的实现方式请戳
这一模型核心的思想与Markowitz思想完全相同,只不过Markowitz没有考虑风险厌恶系数。笔者曾经实现过,回测结果表明模型显著。今天就不贴上来了,下面主要讲Black-Litterman的核心思想:如何将观点与贝叶斯先后验问题融入资产配置模型。
刚刚说了贝叶斯的基本原理:
令A:市场观点;B:投资者观点;B | A:投资者基于市场观点下自己的观点;A | B:基于投资者观点的预期收益。利用贝叶斯公式,可以求得基于投资者观点的预期收益的分布,也即P(A | B)。然后求得最优资产配置。
令:
Π应该是*解出的均衡风险收益。由于资产组合的先验收益μ符合:
则:
其中,τ是不确定性度量。关于如何估测τ值超出了范围,我们姑且采用0.05。
下面是观点矩阵。对于每一类资产,投资者都有一个观点。它可能是绝对观点(未来这一类资产会表现较好),也可能是相对观点(未来某一类资产会比标普500差)。为了表述这种观点,我们采用矩阵:
比如说,有三类资产A,B,C. 某一个投资者认为:
A资产未来年收益率会高于C资产2%
B资产收益率被低估了3%
C资产未来收益率比B资产低1%
那么,令:
同时,投资者会对自己的观点有一定的信心,我们称之为信心矩阵:
其中,wi代表对于每个观点的信心。绝对信心则为1。
将上式代入贝叶斯法则,即可得到带有主观观点的Black-Litterman模型下,预期收益的后验分布。由于推导过程较复杂就不贴出来了,结果如下:
这就是我们最终计算出的最终贝叶斯后验收益率分布。这时候,计算权重本身又成了一个凸优化问题:
只不过,其中的r变成了P(A|B)的期望值。最后的结果相当复杂:
令:
解得:
这个解就是我们最终得到的Black-Litterman模型下的资产配置。
对于十个标的资产,我们采用每5天调仓,历史样本长度取一年(260天),放进模型计算。另外,我们不对模型输入任何观点。也就是投资人对于任何一类观点都是中性的。在调仓日时,调至每天的权重,最后计算收益、回撤和夏普比率。同时,添加限制条件:任何一个大类资产的任何一次仓位权重不超过40%;任何一次调仓时任何一个大类资产的改变不超过10%。
历史回测下资产净值表现如图:
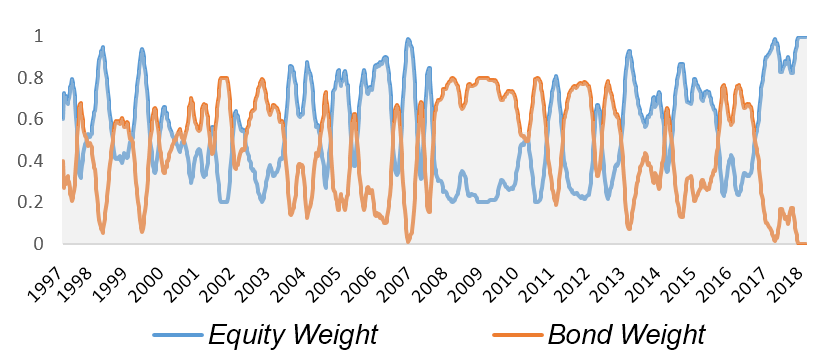
大类资产历史仓位如图:
收益、最大回撤、夏普比率如图:
最终通过Black-Litterman在中性观点测度下的资产配置模型,资产配置得到了明显的优化。
最后说个彩蛋。笔者前几天去参加了摩根大通大类资产配置的比赛,我们团队设计的模型进了全国五强。这一篇Black-Litterman是我从整个模型剥离出来的一部分。之后我将会为大家带来整个模型中用到的其他手段,和大家一起学习~
#欢迎来到 Black-Litterman模型代码实现。代码有些许复杂,是因为这是我们整个回测框架的一部分。from cvxopt import matrix, solversdef blacklitterman_weight_result(df_change,date,window):#注意,大家要自己用这个函数的话,需要自行导入标的资产的历史表现。导入成一个dataframe,列索引为标的资产的名字,行索引为日期#注意,大家要自己用这个函数的话,需要自行导入标的资产的历史表现。导入成一个dataframe,列索引为标的资产的名字,行索引为日期#注意,大家要自己用这个函数的话,需要自行导入标的资产的历史表现。导入成一个dataframe,列索引为标的资产的名字,行索引为日期#这里,df_change是每一个大类资产的历史收益的dataframe,date是整个模型的运行的天数(也就是上面一个dataframe的第date行)。window是样本长度,可任意修改。df=df_change.loc[(date-window-1):date-1]if len(df.columns) == 0:name0=['SP500', 'MSCIEU', 'TOPIX', 'HS300', 'MSCIAPJ', 'MSCIEM', 'IG', 'HY', 'GB', 'EMD']#注意自己使用的时候把这个改成dataframe的列索引(各个标的的名字)df_bl_weight_result=pd.DataFrame([0.0 for i in range(10)],index=name0)df_bl_weight_result.columns=['value']else:name1_=list(df.columns)h0=pd.Series([0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4],['SP500', 'MSCIEU', 'TOPIX', 'HS300', 'MSCIAPJ', 'MSCIEM', 'IG', 'HY', 'GB', 'EMD'])#注意自己使用的时候把第二个list这个改成dataframe的列索引(各个标的的名字)h1=np.matrix(h0[name1_]).Tview_list=[0 for i in range(10)] #这个list代表对于每一个资产的观点。1代表看好,0代表中立,-1代表看空risk*erse=0.30 #风险厌恶系数deltaPAI=np.matrix(df.mean()).TEpsilon=np.matrix(df.cov()) #绝对协方差矩阵EpsilonP=matrix(np.eye(len(df.columns)))for i in range(len(name1_)):if view_list[name1_[i]] == 1:P[i,i] = 1elif view_list[name1_[i]] == -1:P[i,i] = -1elif view_list[name1_[i]] == 0:P[i,i] = 0else:raise ValueErrorP=np.matrix(P)Q=[0.05 for i in range(len(df.columns))] #————————————————待修改项Q=np.matrix(matrix(Q)) #绝对观点矩阵QO=np.matrix(0.10*np.eye(len(df.columns))) #绝对观点偏误矩阵omegatao=0.05 #不确定性度量taomiu_bar=((tao*Epsilon).I+P.T*O.I*P).I*((tao*Epsilon).I*PAI+P.T*O.I*Q) P=risk*erse*matrix(Epsilon)q=-1.0*matrix(miu_bar)A=[]for i in range(len(df.columns)):A.append([1.0])A=matrix(A)b=matrix([[min(sum(h0[name1_]),1.0)]])G=matrix(np.row_stack((-1.0*np.eye(len(df_change.columns)),1.0*np.eye(len(df_change.columns)))))h=matrix(np.row_stack((np.matrix(np.zeros(len(df_change.columns))).T,h1)))try:sol=solvers.qp(P=P,q=q,G=G,h=h,A=A,b=b)result=list(sol['x'].T)df_bl_weight_result=pd.DataFrame(result,index=name1_)df_bl_weight_result.columns=['value']except (ValueError):df_bl_weight_result=equal_weight_result(df_change=df,window=window,date=date)if sum(df_bl_weight_result['value'].values) > 1.001:print('——————','Value>1')print(P,q,A,b,G,h)return df_bl_weight_result

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...