过年怎么能不学习呢!前一阵子看到更新了关于循环神经网络的文章,想基于那篇文章的基础上写一篇关于LSTM的文章。
在实际应用中,最有效的序列模型称为门控RNN (gated RNN)。包括基于长短期记忆(long short-term memory LSTM)和基于门控循环单元(gated recurrent unit GRU)的网络。
就像渗透单元一样,门控RNN的想法也是基于生成通过时间的路径,其中导数既不消失也不发生爆炸,渗漏单元通过手动选择常量的连接权重或参数化的连接权重来达到这一目的,而门控RNN将其推广为在每个时间步都可能改变的连接权重。
本文主要介绍的就是门控RNN中的LSTM。
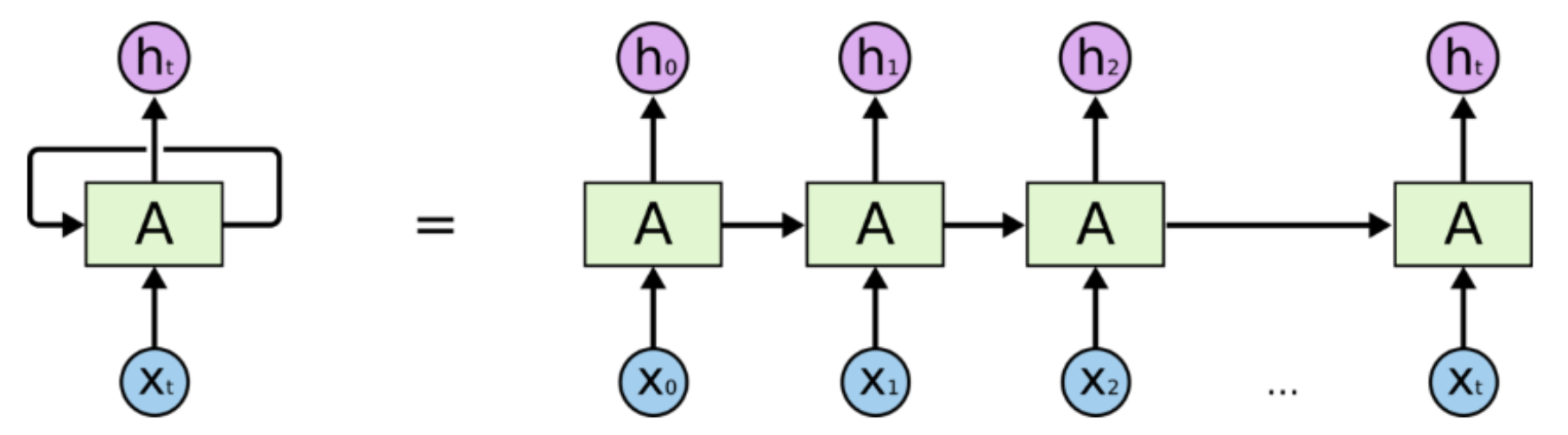
LSTM就是一种特殊的RNN,它通过刻意的设计来避免长期依赖问题,从而学习长期依赖信息。通俗来讲就是说我们可以用LSTM处理时间序列数据中间隔和延迟较长的重要事件。不过既然LSTM是特殊的RNN,那么肯定是需要一定的RNN基础,关于RNN的详细介绍可以去看TensorFlow 学习之循环神经网络(RNN),下图中展示的即为普通的RNN模型(没有输出)。
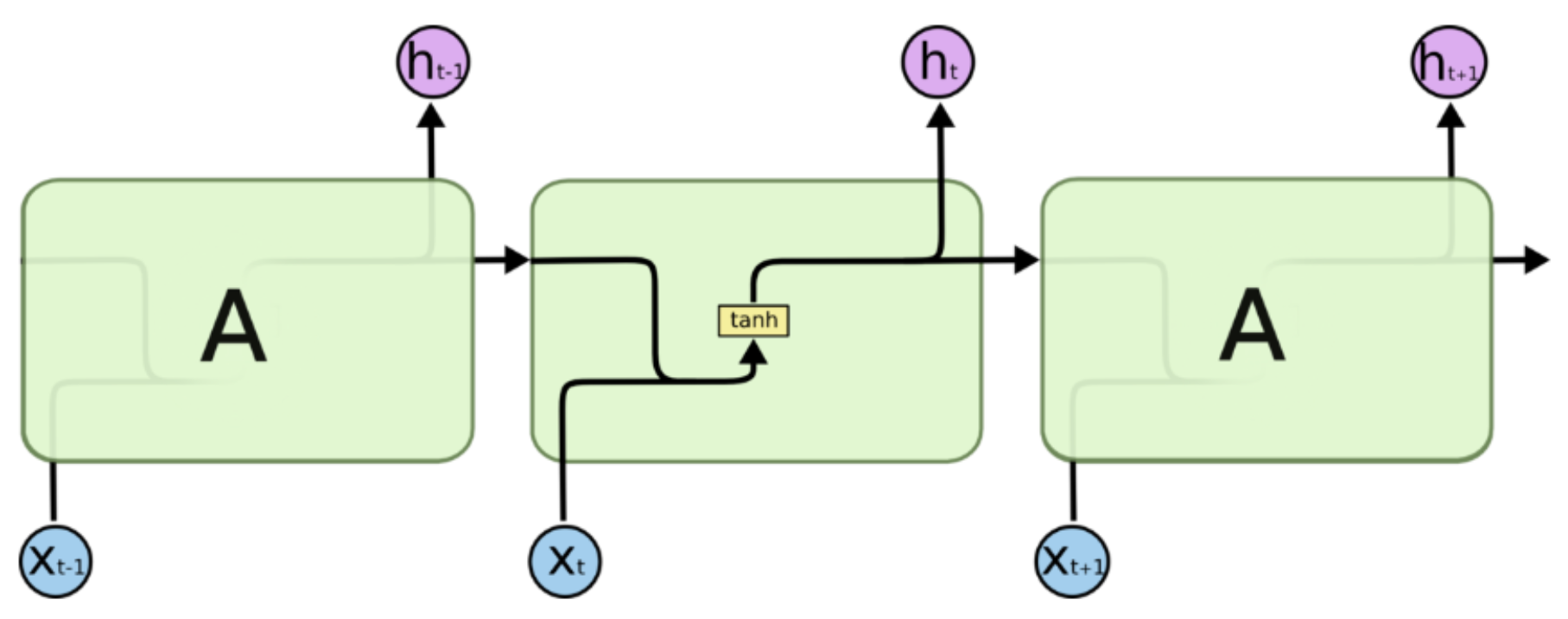
那数据究竟是如何处理的呢,我们把模型图再细致的展开一下,可以看到下图
在图中我们可以看到实际的运算流程,状态
图中乍一看多了很多的内容,不过没关系!我们一点一点来梳理!
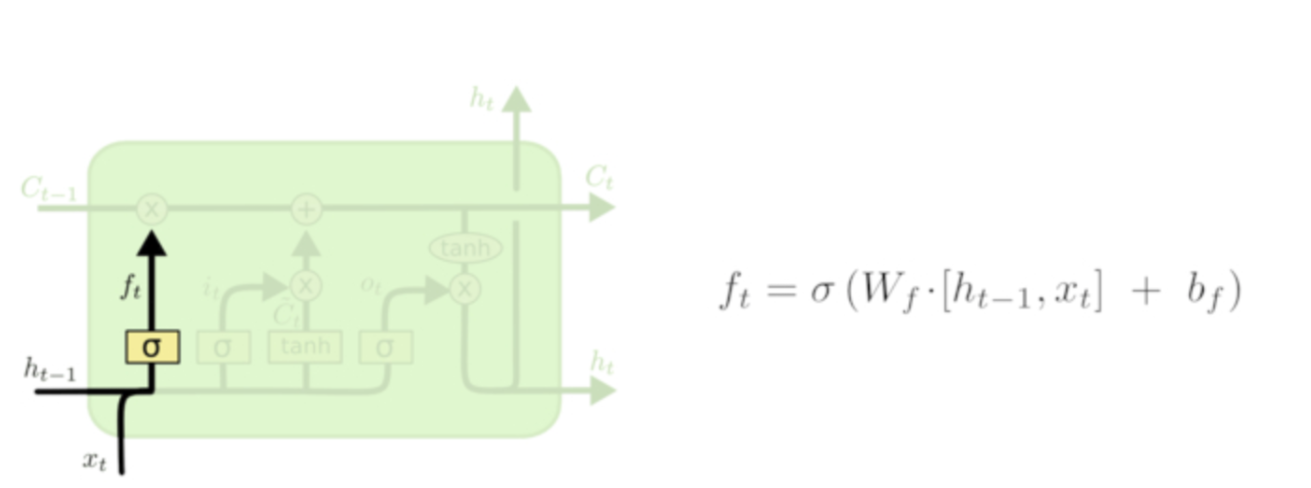
在图中可以看得到有两条横线,上面的那条线是整个LSTM的关键,信息会储存在上面,我们成它为主线。
但是只有这条线的话信息既没有办法增加也没有办法减少,所以就需要下面那条线对数据进行处理,选择性的对上面线中储存的信息进行调整。这个结构叫做门。接下来我们一步一步的介绍信息是如果来处理的。
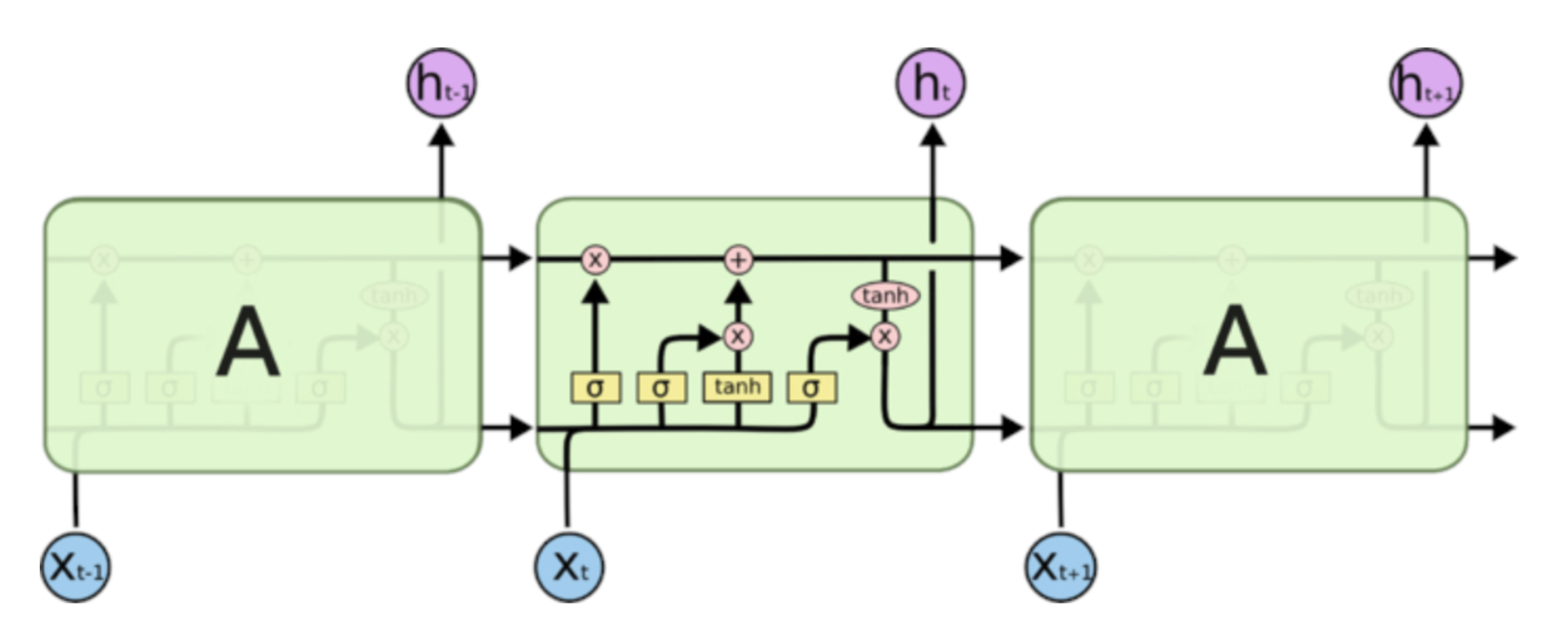
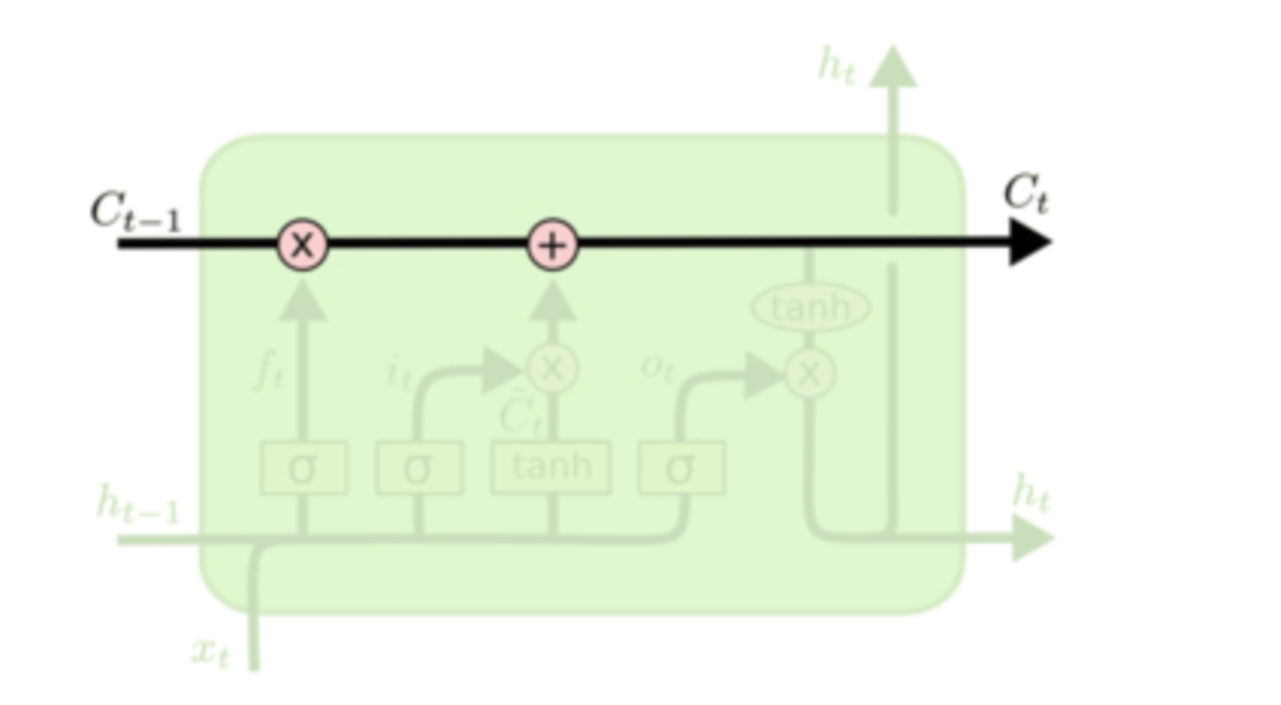
信息输入的第一步就是我们要决定在主线中丢弃什么信息,输入的
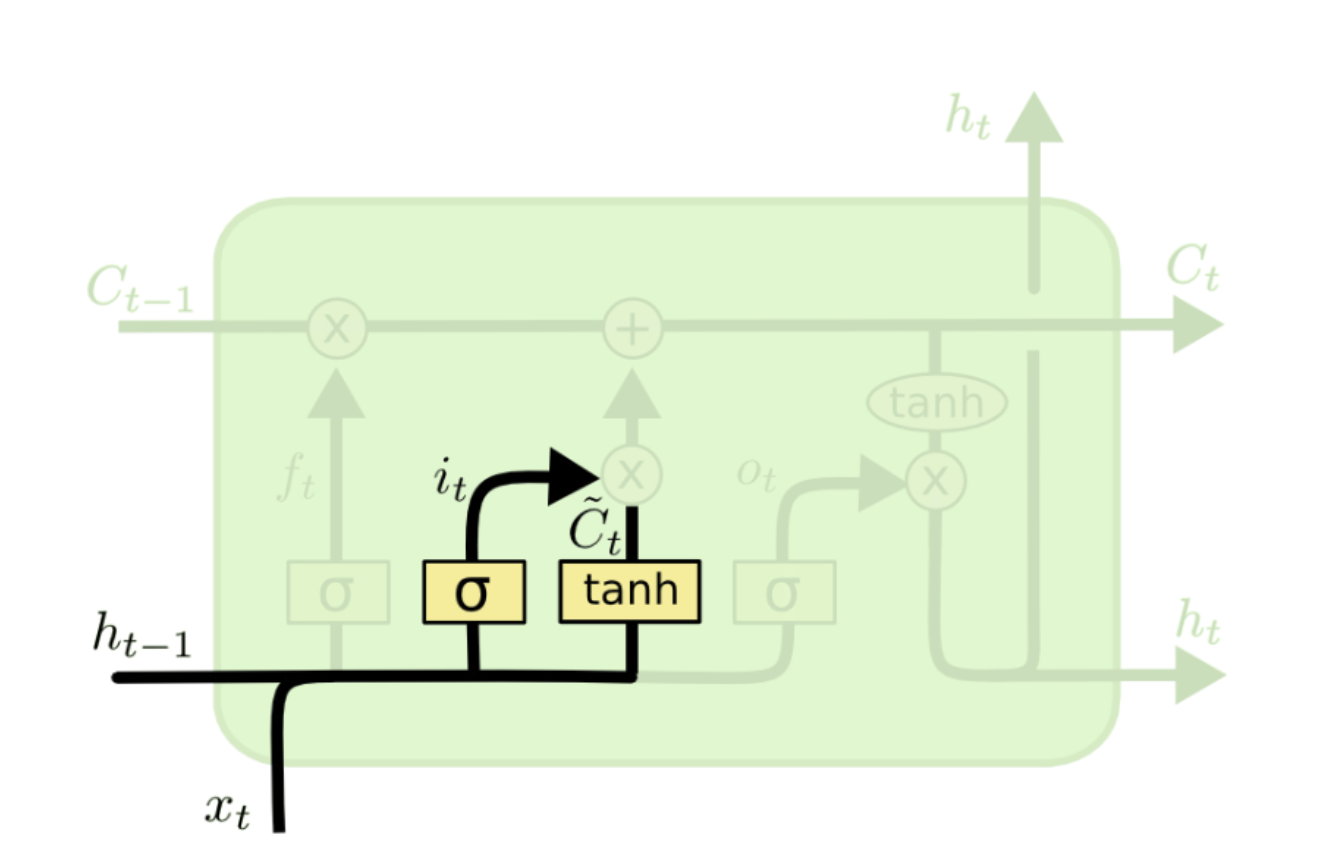
通过输入门可以选择让新的信息加入到主线中来,这里包括了两个步骤,首先通过sigmoid函数决定哪些信息需要更新,在通过tanh函数生成备选用来更新的内容,将这两部分联合起来(相乘),就对主线进行更新。这步进行完之后主线就从
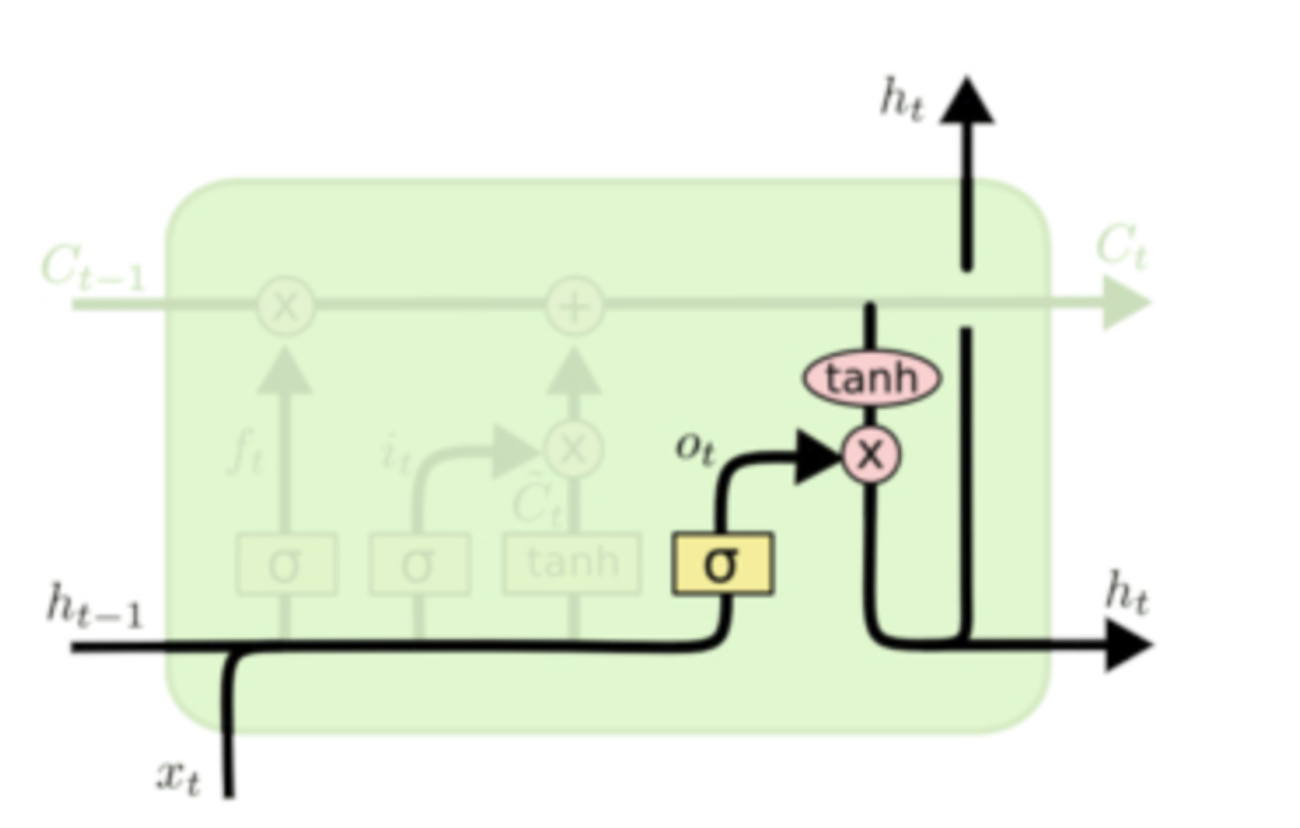
最终,我们需要确定输出什么值。这个输出将会基于我们的主线状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 函数来确定细胞状态的哪个部分将输出出去。接着,我们把主线状态通过 tanh 函数进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
LSTM的内部结构就讲完了,对于LSTM模型的实现可以见下方
由于LSTM是特殊的RNN,整体的结构和RNN是相同的,所以代码参照了之前的文章TensorFlow 学习之循环神经网络(RNN)
第一步,载入需要用到的包
import tensorflow as tf
import numpy as np
import pandas as pd
#函数用于清除默认图形堆栈并重置全局默认图形
tf.reset_default_graph()
第二步,对输入值和输出值进行设定。
#数据定义
#输入值x:以当天沪深300指数的开盘价、收盘价、最高价、最低价为输入数据
x_temp=get_price('000300.XSHG',start_date='2018-01-01',end_date='2018-12-31')[0:-1].iloc[:,:-2]
#将x调整为TensorFlow的格式(由于tf处理数据的格式需要改成float32)
x=tf.Variable(np.array(x_temp).astype(np.float32))
#输出值y:以第二天沪深300指数的收盘价作为输出数据
y_temp=get_price('000300.XSHG',start_date='2018-01-01',end_date='2018-12-31')[1:]['close']
#将y调整为TensorFlow的格式
y_temp=pd.DataFrame(y_temp)
y=tf.Variable(np.array(y_temp).astype(np.float32))
第三步:定义循环神经网络(RNN)的构成图与一些参数
因为LSTM的整体结构还是RNN的结构,所以大体上是不会变化的,只是在隐藏层的处理中要用到不同的函数。
#设置学习率为0.1
lr=0.1
#设置隐藏层的层数为128
hidden_units=128
#输入参数的维度
x_inputs=len(x_temp.columns)
#输入数据的长度
n_step=len(x_temp.index)
#输出的维度
y_output=len(y_temp.columns)
第四步,随机定义各个权重,这里需要设置的有x输入的权重U和输出的权重V,隐藏层的权重W可以不用自己设定
#设置权重,权重为随机数
weights={
'U':tf.Variable(tf.constant(0.25,shape=[x_inputs, y_output])),
'V':tf.Variable(tf.random_normal([hidden_units, n_step])),
}
biases={
'U':tf.Variable(tf.constant(0.0, shape=[n_step,y_output])),
'V':tf.Variable(tf.constant(0.0, shape=[n_step,])),
}
第五步,前期的准备已经OK了,接下来要按照LSTM的整体构架来计算出估计的y值,其他的和RNN都相同,不同的地方在于对隐藏层的处理,需要用到tf.nn.rnn_cell.LSTMCell,这是一个比较基本的创建LSTM细胞的一个类,代码如下:
(1)计算隐藏层的输入数据
x_in = tf.matmul(x, weights['U']) biases['U']
x_in = tf.reshape(x_in, [-1, n_step, y_output])
(2)定义隐藏层的处理方式和计算出输出值
#定义隐藏层的处理方式(这里的函数是可以自行选择的~可以多去探索一下呦)
cell = tf.nn.rnn_cell.LSTMCell(hidden_units)
#计算出隐藏层中每层的结果
outputs, states = tf.nn.dynamic_rnn(cell, x_in, dtype=tf.float32)
#outputs记录了隐藏层中每一层的输出,但是如果要计算出最后的输出,只需要最后一层即可
output = tf.transpose(outputs, [1,0,2])[-1]
#根据权重得到对y的估计值
results=tf.matmul(output, weights['V']) biases['V']
(3)求出预测的误差,再根据误差大小和学习率用优化器调整权重设置。
#算误差
cost=tf.reduce_mean(tf.square(results-y))
#根据误差大小和学习率用优化器调整权重设置
train_op = tf.train.AdamOptimizer(0.1).minimize(cost)
第六步,进行多遍循环运行来调整权重以缩小误差,并查看误差
#初始化
init = tf.global_variables_initializer()
#构建一个图
sess = tf.Session()
#先把图初始化
sess.run(init)
#运行30000次来调整权重,每1000次打印出误差和预测的y值
for i in range(30000):
sess.run(train_op)
if i % 1000 == 0:
#由于学习出的结果过多,这里只显示最后一个值
print(sess.run(cost),sess.run(results[-1][-1]))
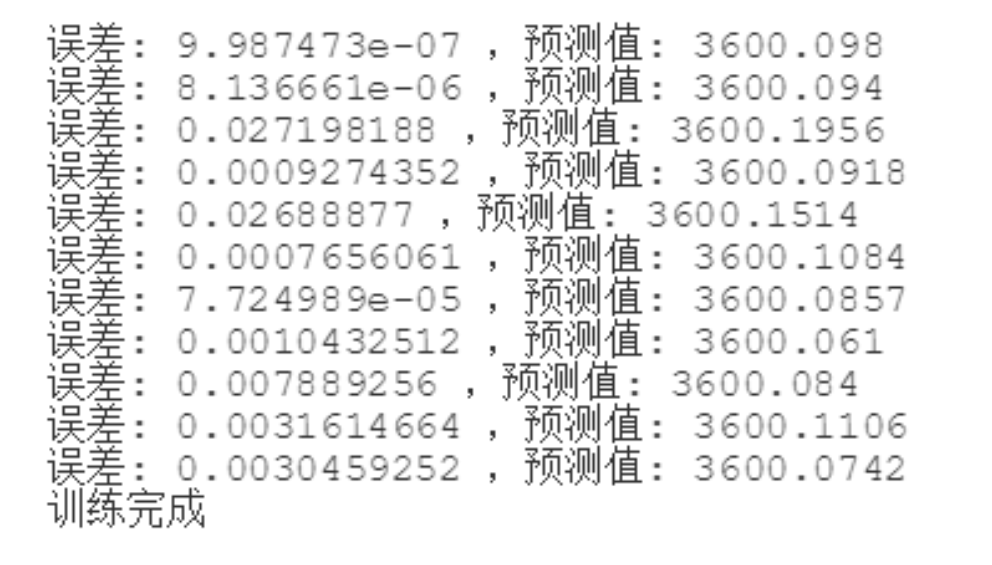
最后通过运行就可以看到训练的结果。
LSTM就到这里就结束了!欢迎指正批评!
注:本文参考了LSTM原理及实现
import tensorflow as tf
import numpy as np
import pandas as pd
#函数用于清除默认图形堆栈并重置全局默认图形
tf.reset_default_graph()
/opt/conda/envs/python3new/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6 return f(*args, **kwds)
#数据定义
#输入值x:以当天沪深300指数的开盘价、收盘价、最高价、最低价为输入数据
x_temp=get_price('000300.XSHG',start_date='2018-01-01',end_date='2018-12-31')[0:-1].iloc[:,:-2]
#将x调整为TensorFlow的格式(由于tf处理数据的格式需要改成float32)
x=tf.Variable(np.array(x_temp).astype(np.float32))
#输出值y:以第二天沪深300指数的收盘价作为输出数据
y_temp=get_price('000300.XSHG',start_date='2018-01-01',end_date='2018-12-31')[1:]['close']
#将y调整为TensorFlow的格式
y_temp=pd.DataFrame(y_temp)
y=tf.Variable(np.array(y_temp).astype(np.float32))
#设置学习率为0.1
lr=0.1
#设置隐藏层的层数为128
hidden_units=128
#输入参数的维度
x_inputs=len(x_temp.columns)
#输入数据的长度
n_step=len(x_temp.index)
#输出的维度
y_output=len(y_temp.columns)
#设置权重,权重为随机数
weights={
'U':tf.Variable(tf.constant(0.25,shape=[x_inputs, y_output])),
'V':tf.Variable(tf.random_normal([hidden_units, n_step])),
}
biases={
'U':tf.Variable(tf.constant(0.0, shape=[n_step,y_output])),
'V':tf.Variable(tf.constant(0.0, shape=[n_step,])),
}
x_in = tf.matmul(x, weights['U'])+biases['U']
x_in = tf.reshape(x_in, [-1, n_step, y_output])
#定义隐藏层的处理方式(这里的函数是可以自行选择的~可以多去探索一下呦)
cell = tf.nn.rnn_cell.LSTMCell(hidden_units)
#计算出隐藏层中每层的结果
outputs, states = tf.nn.dynamic_rnn(cell, x_in, dtype=tf.float32)
#outputs记录了隐藏层中每一层的输出,但是如果要计算出最后的输出,只需要最后一层即可
output = tf.transpose(outputs, [1,0,2])[-1]
#根据权重得到对y的估计值
results=tf.matmul(output, weights['V']) + biases['V']
#算误差
cost=tf.reduce_mean(tf.square(results-y))
#根据误差大小和学习率用优化器调整权重设置
train_op = tf.train.AdamOptimizer(0.1).minimize(cost)
#初始化
init = tf.global_variables_initializer()
#构建一个图
sess = tf.Session()
#先把图初始化
sess.run(init)
#运行30000次来调整权重,每1000次打印出误差和预测的y值
for i in range(10000):
sess.run(train_op)
if i % 1000 == 0:
#由于学习出的结果过多,这里只显示最后一个值
print(sess.run(cost),sess.run(results[-1][-1]))
1.31014e+07 16.6143 569426.0 2888.1

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程