一、前言
量化投资从方法论上可分为两大门派,一是技术派,通过技术指标预测未来走势,基于纯数据分析或者结合行为金融学等知识,多用于预测短期行情。特点是交易频次高,延时要求小。另一派可称为价值投资派,主要通过对宏观经济、行业、企业基本面等数据分析,依据经济学、金融学等原理,综合考量,用于预测未来走势。特点是交易频次低,着眼与长远。当今世界的投资界高手大多奉行价值投资理念,例如巴菲特。
对于价值投资而言,宏观、中观、微观三个维度分别对应宏观经济分析,行业分析和企业基本面分析,三个维度对于成熟投资策略缺一不可。虽说三个维度都很重要,但对于A股市场而言,我个人认为宏观判断最为重要。因为A股市场散户比例较高,行情走势受市场情绪影响较大,大部分情况下都是同涨同跌,这意味着A股市场的波动更多的反映的是系统性风险,而非个股的个体性风险。
宏观经济走势是会对系统性风险产生极大影响。例如2018年下半年,由于宏观经济政策调整,资管新规、金融去杠杆、中美贸易摩擦等一系列宏观事件使宏观数据走低,又进一步影响市场预期,造成股指大幅下滑。2018年底到2019年初,前期宏观政策效果开始凸显,货币政策开始趋于宽松,市场预期改变,部分宏观数据开始走好,3月份PMI超预期,这一系列信号是2019年初股市回暖的最重要因素。所以,宏观经济走势的判断是预测股市最重要的因素。宏观趋势判断准确,在牛市,即便是垃圾股也大概率会上涨,在熊市,好股票也会跟着遭殃。
宏观择时是基础,行业和个股分析是锦上添花。
宏观择时可以在买入卖出两个方向上盈利,本文只研究了股票市场。
二、研究目标
通过对宏观经济数据分析,找到具备预测能力的择时策略。
三、使用数据
本文策略使用聚宽提供的宏观数据。聚宽尚无日频数据,年度和季度数据滞后性较大,所以只使用月度数据。不同指标的月度数据延时不同,例如:PMI的延时为1个月,即本月可知上月数据,固定资产投资情况延迟2个月,消费者信息指数延迟3个月。
回测时间为2010-01至2019-03
四、数据处理方法
利用最近的宏观数据判断当前走势。方法分三种:
(1)连续走势,例如数据连续2个月上涨,则认为处于上升趋势;
(2)移动平均,例如3日移动平均值,如果当期大于上期则认为处于上升趋势;
(3)长短均线,例如3日均线向上突破10日均线,认为处于上升趋势。
(4)上述三种方法合并,如果有两个预测一致,则取该预测值。
对所有月度数据用上述三种方式处理,计算收益情况和胜率,判断那种方法更有效。借此筛选出有预测能力的数据和处理方法。
例如,对制造业采购经理指数数据处理结果如下:
net_value是基准收益,net_value_timing是因子择时后收益,win_rate是胜率。通过观察可以发现pmi具备择时能力,可以作为择时因子。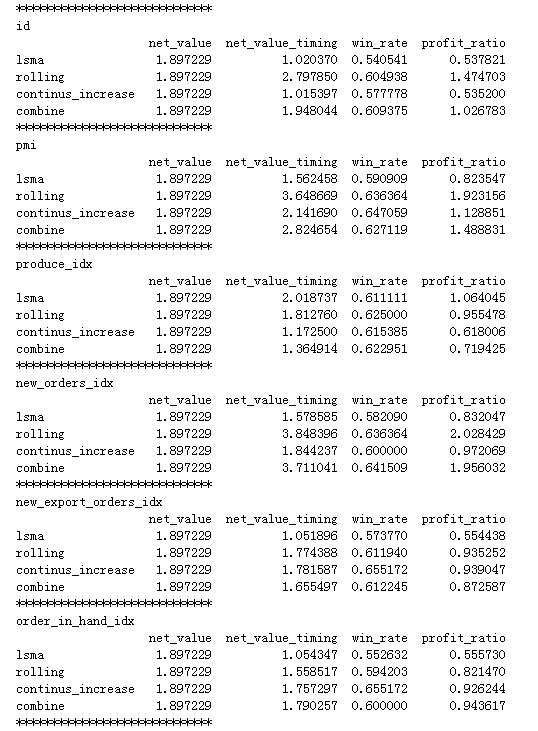
对所有月度数据遍历后发现,具备择时能力的因子有:
1.PMI 延时1个月,连续走势效果最好
2.import_idx 延时1个月,连续走势效果最好
3.primary_yoy 延时2个月,移动平均效果最好
4.satisfaction_idx 延时3个月,合并效果最好
5.confidence_idx 延时3个月,合并效果最好
五、单因子预测效果
PMI预测效果:
进口指数预测效果: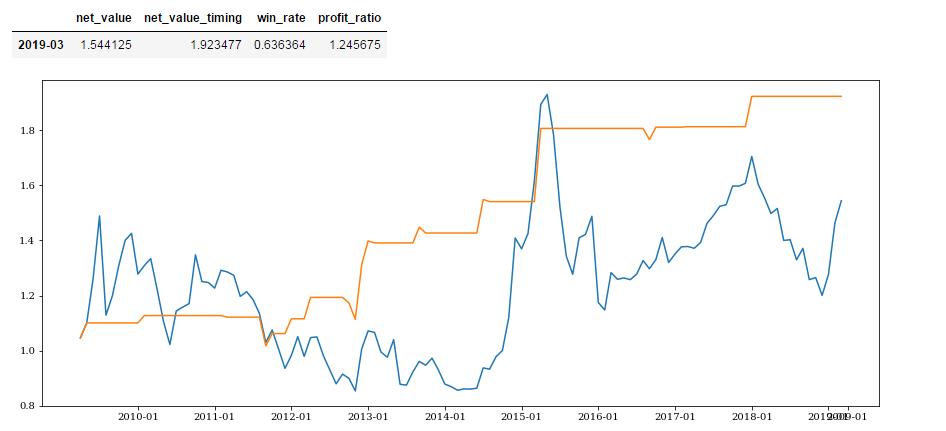
第一产业固定资产投资完成额_累计增长预测效果: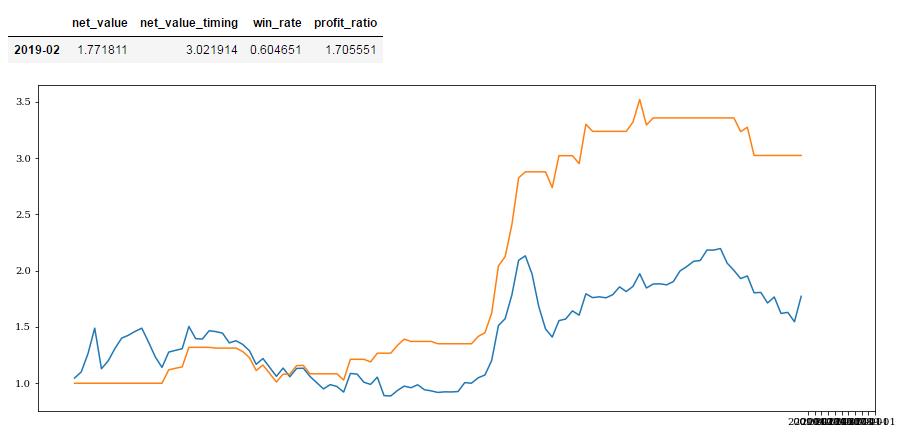
消费者满意指数预测效果: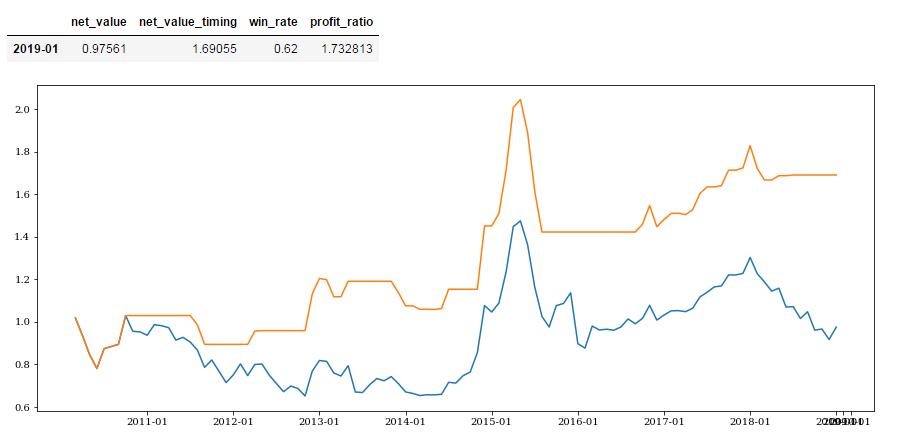
消费者信心指数预测效果: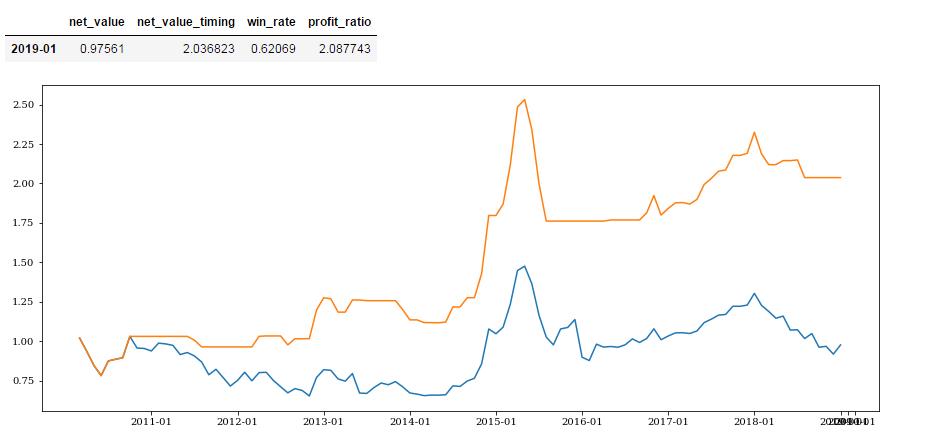
六、多因子择时
将单个因子的预测能力结合,形成多因子策略。方式为将各个因子的预测值按权重求和,设置门限值确定最终持仓情况。
五个因子权重相同时预测效果如下: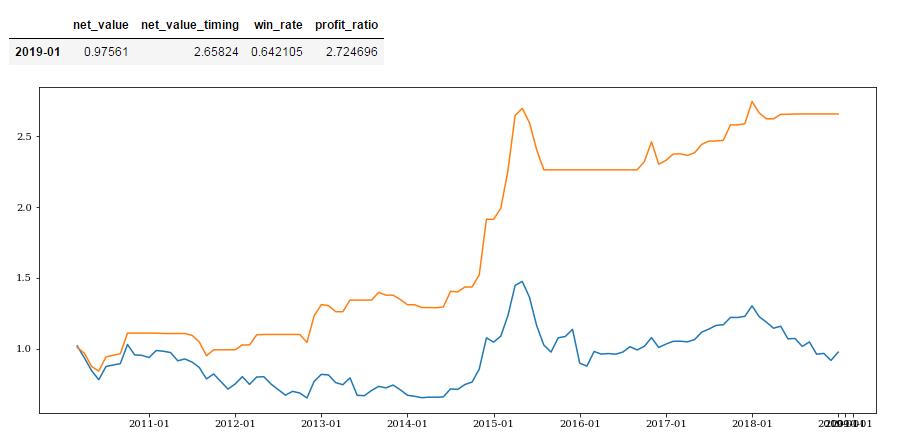
由于进口指数和PMI、消费者信心指数和消费者满意指数具有一定的相关性,所以调整权重,降低进口指数和消费者满意指数比例,无论是胜率还是收益率都有所提升。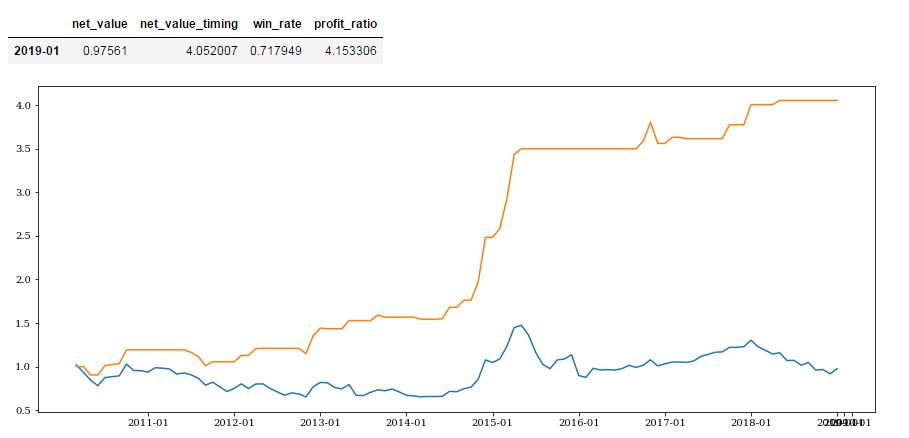
由于进口指数和PMI、消费者信心指数和消费者满意指数具有一定的相关性,所以调整权重,降低进口指数和消费者满意指数比例,无论是胜率还是收益率都有所提升。
上篇文章研究了其他指标的择时策略,
将结果用pickle保存后提取,此系列因子的预测效果如下: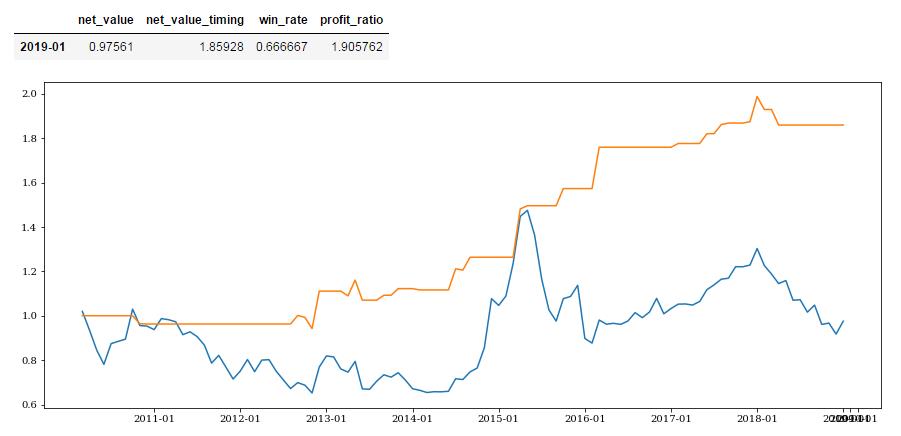
将本文因子与之合并后预测效果如下: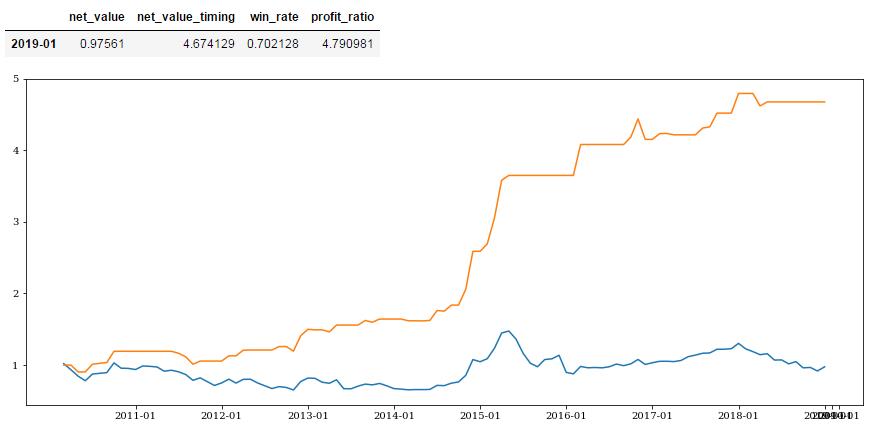
七、回测效果
本文策略回测效果如下: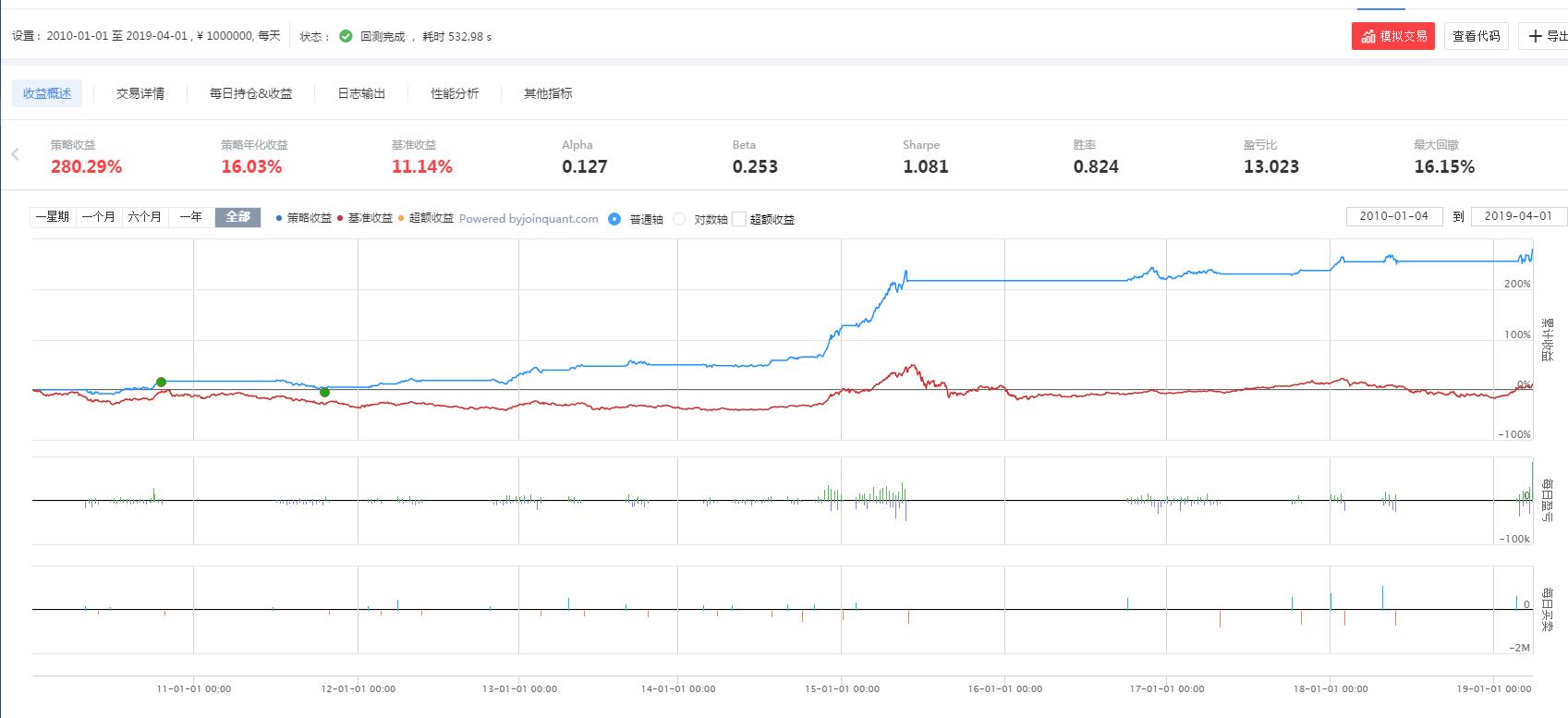
策略收益是基准收益的27倍,年化收益16%,胜率82.4%,最大回撤16%。
如果配合股指期货做空,收益会更高。
八、不足之处
(1)策略交易次数少,会出现长期空仓的情况,一方面这是策略优势,在判断下行周期时长期不发出买入信号,但另一方面,就实际而言,长期的空仓是无法忍受的,尤其是在出现小波行情时。其实在空仓期可以买入固定收益率产品,还可以有一部分收益,策略中没有体现,若考虑此部分收益,收益会更好。
(2)对于部分行情还是没能判断出来,这可能是由于因子选择和处理方式没能提供充分信息。
(3)此策略在许多细节处还有改进空间,例如交易日是否是每月第一天,因子组合的方式,权重的设置,新因子的构造等。
(4)在研究方法上,基于过去的数据挑选,又基于过去的数据预测,有过度调参的嫌疑,但是通过收益曲线可以看出,整体处于上升趋势,在不同时期都有向上表现,侧面反应出稳定性。另外,选择的预测因子在经济学原理上有较强的解释性,提高了可信度。
from jqdata import *import numpy as npimport pandas as pdimport datetime as dtfrom six import StringIOfrom dateutil.parser import parseimport pickleimport seaborn as snsimport matplotlib as mplimport matplotlib.pyplot as pltimport osimport statsmodels.api as smimport scipyimport talib as tlimport warningswarnings.filterwarnings('ignore')mpl.rcParams['font.family']='serif'mpl.rcParams['axes.unicode_minus']=False # 处理负号def get_profit(data,start_date,end_date,rate_riskfree=0):df_pct=pd.DataFrame()prices = get_price('000300.XSHG',start_date=start_date,end_date=end_date,fields='close')['close']df_pct['pct']=prices.pct_change()rate_riskfree = 0df_pct = pd.concat([df_pct,data],axis=1)[start_date:end_date].dropna()df_pct['net_value'] =(df_pct['pct']+1).cumprod()df_pct['net_value_timing'] = (df_pct['pct']*df_pct['position']+rate_riskfree*(1-df_pct['position'])+1).cumprod()df_pct[['net_value','net_value_timing']].plot(figsize=(15,6))return df_pct#此函数调试用,部分情况下dataframe中有部分元素非实数def get_float(data):''' 将dataframe中的str类型转换成float data:dataframe '''values = data.valuesindex = data.indexcolumns = data.columnsl = []for ind in range(len(index)):ind_list = []for col in range(len(columns)):f = float(values[ind][col])ind_list.append(f)l.append(ind_list)df = pd.DataFrame(l, index=index, columns=columns)return dfdef bbands_select_time(data,model='up'):col = data.columns[0]upperband,middleband,lowerband = (tl.BBANDS(data[col].values, timeperiod=25, nbdevup=1.8, nbdevdn=1.8))data['BBAND_upper']=upperbanddata['BBAND_middle']=middlebanddata['BBAND_lower']=lowerbandpre_position = 0if model == 'up':for date in data.index:if data.loc[date,col]<data.loc[date,'BBAND_middle']:data.loc[date,'position']=0elif data.loc[date,col]>data.loc[date,'BBAND_upper']:data.loc[date,'position']=1.0else:data.loc[date,'position']=pre_positionpre_position=data.loc[date,'position']data['position']=data['position'].shift(1)elif model == 'lower':for date in data.index:if data.loc[date,col]>data.loc[date,'BBAND_middle']:data.loc[date,'position']=0elif data.loc[date,col]<data.loc[date,'BBAND_lower']:data.loc[date,'position']=1.0else:data.loc[date,'position']=pre_positionpre_position=data.loc[date,'position']data['position']=data['position'].shift(1)return datadef get_month_list(start_date, end_date):sy = int(start_date[:4])ey = int(end_date[:4])sm = int(start_date[5:7])em = int(end_date[5:7])l = []for y in range(sy, ey + 1):if y == sy:for i in range(sm, 13):if i < 10:s = str(y) + '-' + '0' + str(i)l.append(s)else:s = str(y) + '-' + str(i)l.append(s)elif y == ey:for i in range(1, em + 1):if i < 10:s = str(y) + '-' + '0' + str(i)l.append(s)else:s = str(y) + '-' + str(i)l.append(s)else:for i in range(1, 13):if i < 10:s = str(y) + '-' + '0' + str(i)l.append(s)else:s = str(y) + '-' + str(i)l.append(s)return ldef get_profit_monthly(data,start_date,end_date,rate_riskfree=0):''' data:position数据,1列,前期计算出择时position start_date:datetime or str, 开始时间,此时间要和data时间有交集,通常是对应 end_date:结束时间 rate_riskfree:无风险利率 '''df_pct=pd.DataFrame()prices = get_price('000300.XSHG',start_date=start_date,end_date=end_date,fields='close')['close']prices_M = prices.resample('M',how='last')month_list = get_month_list(start_date,end_date)prices_M.index = month_listdf_pct['pct']=prices_M.pct_change()rate_riskfree = 0df_pct = pd.concat([df_pct,data],axis=1).loc[month_list].dropna()df_pct['net_value'] =(df_pct['pct']+1).cumprod()df_pct['net_value_timing'] = (df_pct['pct']*df_pct['position']+rate_riskfree*(1-df_pct['position'])+1).cumprod()f = plt.figure(figsize=(15,6))ax = f.add_subplot(1,1,1)ax.plot(df_pct[['net_value','net_value_timing']])ax.set_xticks(month_list[::12])return df_pctdef get_profit_res(data,start_date,end_date,rate_riskfree=0,plot=True):''' data:position数据,1列,前期计算出择时position start_date:datetime or str, 开始时间,此时间要和data时间有交集,通常是对应 end_date:结束时间 rate_riskfree:无风险利率 '''df_pct=pd.DataFrame()prices = get_price('000300.XSHG',start_date=start_date,end_date=end_date,fields='close')['close']prices_M = prices.resample('M',how='last')month_list = get_month_list(start_date,end_date)prices_M.index = month_listdf_pct['pct']=prices_M.pct_change()df_pct['pct_position'] = df_pct['pct']df_pct['pct_position'][df_pct['pct_position']>0] = 1df_pct['pct_position'][df_pct['pct_position']<0] = 0rate_riskfree = 0df_pct = pd.concat([df_pct,data],axis=1).loc[month_list].dropna()#计算胜率win_rate = df_pct['position'] * df_pct['pct_position']win_rate = win_rate.sum()/df_pct['position'].sum()df_pct['net_value'] =(df_pct['pct']+1).cumprod()df_pct['net_value_timing'] = (df_pct['pct']*df_pct['position']+rate_riskfree*(1-df_pct['position'])+1).cumprod()if plot == True:f = plt.figure(figsize=(15,6))ax = f.add_subplot(1,1,1)ax.plot(df_pct[['net_value','net_value_timing']])ax.set_xticks(month_list[::12])profit_res = df_pct.ix[-1,['net_value','net_value_timing']].to_frame().stack().unstack(0)profit_res['win_rate'] = win_rateprofit_res['profit_ratio'] = profit_res['net_value_timing'] / profit_res['net_value']return profit_resdef get_rolling_positon(data,n,delay=2,how='up'):''' data:dataframe or series,输入数据,必须是一列 n:移动平均窗口大小 delay:取决于宏观数据发布时间,一般宏观数据都是本月中旬发布上月数据,每月初能拿到的最近数据为2月前 '''if how == 'up':position = (data.rolling(n).mean() > data.rolling(n).mean().shift(1))*1.0else:position = (data.rolling(n).mean() < data.rolling(n).mean().shift(1))*1.0if isinstance(position,pd.Series):position = position.to_frame()position.columns = ['position']position = position.shift(delay).dropna()return position
def get_position_from_continus_increase(data,n,delay=2,how='up'):''' data:dataframe or series,输入数据,必须是一列 n:连续n次上涨或下跌 how:默认up,连续上涨n天position标记为1 delay:取决于宏观数据发布时间,一般宏观数据都是本月中旬发布上月数据,每月初能拿到的最近数据为2月前 '''index = list(data.index)length = len(index)l = []for i in range(n,length):if how == 'up':counter = 0for j in range(i-n,i):if data.loc[index[j]]< data.loc[index[j+1]]:counter += 1if counter == n:position = 1l.append(position)else:position = 0l.append(position)else:counter = 0for j in range(i-n,i):if data.loc[index[j]] > data.loc[index[j+1]]:counter += 1if counter == n:position = 1l.append(position)else:position = 0l.append(position)res = pd.DataFrame(l,columns=['position'],index=index[n:])res = res.shift(delay).dropna()return res
def get_position_from_long_short_monving_*erage(data,long_n=12,short_n=3,delay=2,how='up'):''' data:dataframe or series,输入数据,必须是一列 long_n:移动平均长期线计算窗口 short_n:移动平均短期线窗口 n:连续n次上涨或下跌 how:默认up,连续上涨n天position标记为1 delay:取决于宏观数据发布时间,一般宏观数据都是本月中旬发布上月数据,每月初能拿到的最近数据为2月前 ''' long_ma = data.rolling(long_n).mean()short_ma = data.rolling(short_n).mean()diff = short_ma - long_madiff[diff>0] = 1diff[diff<=0] = 0if isinstance(diff,pd.Series):diff = diff.to_frame()diff.columns = ['position']res = diff.shift(delay).dropna()return res
def get_factor_profit_compare(t,delay,rolling_n=3,continus_inc=2,how='up',plot=False):p_lsma = get_position_from_long_short_monving_*erage(t,delay=delay,how=how)p_rolling = get_rolling_positon(t,3,delay=delay,how=how)p_continus_increase = get_position_from_continus_increase(t,2,delay=delay,how=how)p = pd.concat([p_lsma,p_rolling,p_continus_increase],axis=1).dropna()index = p.indexp_lsma = p_lsma.loc[index]p_rolling = p_rolling.loc[index]p_continus_increase = p_continus_increase.loc[index]p_all = (p_lsma + p_rolling + p_continus_increase) / 3.0p_all[p_all > 0.5] = 1p_all[p_all<0.5] = 0profit_lsma = get_profit_res(p_lsma,start_date,end_date,plot=plot)profit_lsma.index = ['lsma']profit_rolling = get_profit_res(p_rolling,start_date,end_date,plot=plot)profit_rolling.index = ['rolling']profit_continus_increase = get_profit_res(p_continus_increase,start_date,end_date,plot=plot)profit_continus_increase.index = ['continus_increase']profit_all = get_profit_res(p_all,start_date,end_date,plot=plot)profit_all.index = ['combine']profit = pd.concat([profit_lsma,profit_rolling,profit_continus_increase,profit_all])profit['profit_ratio'] = profit['net_value_timing'] / profit['net_value']return profit
def get_combine_positon(t,delay,rolling_n=3,continus_inc=2,how='up'):p_lsma = get_position_from_long_short_monving_*erage(t,delay=delay,how=how)p_rolling = get_rolling_positon(t,3,delay=delay,how=how)p_continus_increase = get_position_from_continus_increase(t,2,delay=delay,how=how)p = pd.concat([p_lsma,p_rolling,p_continus_increase],axis=1).dropna()index = p.indexp_lsma = p_lsma.loc[index]p_rolling = p_rolling.loc[index]p_continus_increase = p_continus_increase.loc[index]p_all = (p_lsma + p_rolling + p_continus_increase) / 3.0p_all[p_all > 0.5] = 1p_all[p_all<0.5] = 0return p_all
def check_all_factors(t):col = t.columnsfor c in col:print('****************************')print(c)data_input = t[c].sort_index()profit = get_factor_profit_compare(data_input,delay=2,how='up')print(profit)start_date = '2009-01-01'end_date = '2019-03-29'month_list = get_month_list(start_date,end_date)
#消费者景气指数def get_mac_economic_idx(month_list):mei = macro.MAC_CONSUMER_BOOM_IDXq = query(mei).filter(mei.stat_month.in_(month_list))mac_economic = macro.run_query(q)mac_economic = mac_economic.set_index('stat_month')return mac_economict = get_mac_economic_idx(month_list)t = t.sort_index()satisfaction_idx = t['satisfaction_idx'].sort_index()satisfaction_position = get_combine_positon(satisfaction_idx,delay=3)confidence_idx = t['confidence_idx'].sort_index()confidence_position = get_combine_positon(confidence_idx,delay=0)#print(confidence_position.loc['2014-02':])confidence_position = get_combine_positon(confidence_idx,delay=3)#print(confidence_position.loc['2014-02':])get_profit_res(satisfaction_position,start_date,end_date).dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| net_value | net_value_timing | win_rate | profit_ratio | |
|---|---|---|---|---|
| 2019-01 | 0.97561 | 1.69055 | 0.62 | 1.732813 |
#制造业采购经理指数def get_mac_economic_idx(month_list):mei = macro.MAC_MANUFACTURING_PMIq = query(mei).filter(mei.stat_month.in_(month_list))mac_economic = macro.run_query(q)mac_economic = mac_economic.set_index('stat_month')return mac_economict = get_mac_economic_idx(month_list)t = t.sort_index()t.tail()pmi = t['pmi'].sort_index()pmi_position = get_position_from_continus_increase(pmi,2,delay=1)import_idx = t['import_idx'].sort_index()import_position = get_position_from_continus_increase(import_idx,2,delay=1)get_profit_res(pmi_position,start_date,end_date).dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| net_value | net_value_timing | win_rate | profit_ratio | |
|---|---|---|---|---|
| 2019-03 | 1.544125 | 1.619535 | 0.607143 | 1.048837 |
#第一产业增加值def get_mac_economic_idx(month_list):mei = macro.MAC_FIXED_INVESTMENTq = query(mei).filter(mei.stat_month.in_(month_list))mac_economic = macro.run_query(q)mac_economic = mac_economic.set_index('stat_month')return mac_economict = get_mac_economic_idx(month_list)t = t.sort_index()primary_yoy = t['primary_yoy'].sort_index()primary_position = get_rolling_positon(primary_yoy,3,delay=2)get_profit_res(primary_position,start_date,end_date).dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| net_value | net_value_timing | win_rate | profit_ratio | |
|---|---|---|---|---|
| 2019-02 | 1.771811 | 3.021914 | 0.604651 | 1.705551 |
all_position = pd.concat([pmi_position,import_position,primary_position,satisfaction_position,confidence_position ],axis=1)col = ['PMI','import_idx','primary_yoy','satisfaction_idx','confidence_idx']all_position.columns = col#print(all_position.loc['2013-12':])#timing_count = all_position[all_position[col]>=0].sum(axis=1)all_position = all_position.dropna(subset=['satisfaction_idx','confidence_idx']).fillna(0)#print(all_position.loc['2014-08':])index = all_position.indexweights = [1,0.5,1,0.5,1]combine_position = (all_position[col] * weights).sum(axis=1)df_position = pd.DataFrame(combine_position,index=index,columns=['position'])df_position = df_position / sum(weights)def fun_(x):if x > 0.45:y = 1elif x < 0.4:y = 0else:y = 0.5return ydf_position = df_position.applymap(fun_)#print(df_position.loc['2014-08':])all_profit = get_profit_res(df_position,start_date,end_date)all_profit
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| net_value | net_value_timing | win_rate | profit_ratio | |
|---|---|---|---|---|
| 2019-01 | 0.97561 | 4.052007 | 0.717949 | 4.153306 |
with open('macro_position.pkl','rb') as pf:other_position = pickle.load(pf)other_position_index = other_position.indexstr_index = [dt.datetime.strftime(i,'%Y-%m-%d') for i in other_position_index]cut_index = [i[:7] for i in str_index]other_position.index = cut_indexdf_position_index = df_position.indexother_position = other_position.loc[df_position_index]tot_pos = other_position[['tot_pos']]tot_pos.columns = ['position']other_position = other_position.drop(['tot_pos'],axis=1)other_profit = get_profit_res(tot_pos,start_date,end_date)other_position.loc['2017-06':].dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| monetary | forex | credit | boom | inflation | |
|---|---|---|---|---|---|
| 2017-06 | 0.666667 | 1.0 | 0.5 | 0.0 | 0.0 |
| 2017-07 | 0.333333 | 0.0 | 0.5 | 0.0 | 0.0 |
| 2017-08 | 0.333333 | 1.0 | 0.0 | 1.0 | 1.0 |
| 2017-09 | 0.000000 | 1.0 | 0.0 | 1.0 | 1.0 |
| 2017-10 | 0.000000 | 0.0 | 0.5 | 1.0 | 0.0 |
| 2017-11 | 0.333333 | 0.0 | 0.5 | 1.0 | 0.0 |
| 2017-12 | 0.000000 | 1.0 | 0.0 | 1.0 | 0.0 |
| 2018-01 | 0.000000 | 1.0 | 0.5 | 0.0 | 1.0 |
| 2018-02 | 0.000000 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2018-03 | 0.333333 | 0.0 | 1.0 | 0.0 | 1.0 |
| 2018-04 | 0.333333 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2018-05 | 0.000000 | 0.0 | 0.3 | 1.0 | 1.0 |
| 2018-06 | 0.000000 | 0.0 | 0.3 | 1.0 | 1.0 |
| 2018-07 | 0.333333 | 0.0 | 0.3 | 0.0 | 0.0 |
| 2018-08 | 1.000000 | 0.0 | 0.3 | 0.0 | 0.0 |
| 2018-09 | 0.333333 | 0.0 | 0.3 | 0.0 | 0.0 |
| 2018-10 | 0.000000 | 0.0 | 0.8 | 0.0 | 1.0 |
| 2018-11 | 0.333333 | 0.0 | 0.5 | 0.0 | 1.0 |
| 2018-12 | NaN | NaN | NaN | NaN | 1.0 |
| 2019-01 | NaN | NaN | NaN | NaN | 1.0 |
all_position = pd.concat([pmi_position,import_position,primary_position,satisfaction_position,confidence_position ],axis=1)col = ['PMI','import_idx','primary_yoy','satisfaction_idx','confidence_idx']all_position.columns = col#timing_count = all_position[all_position[col]>=0].sum(axis=1)all_position = all_position.dropna(subset=['satisfaction_idx','confidence_idx']).fillna(0)index = all_position.indexweights = [1,0.5,1,0.5,1]combine_position = (all_position[col] * weights).sum(axis=1)df_position = pd.DataFrame(combine_position,index=index,columns=['position'])df_position = df_position / sum(weights)def fun_(x):if x > 0.45:y = 1elif x < 0.4:y = 0else:y = 0.5return ydf_position1 = df_position.applymap(fun_)all_profit = get_profit_res(df_position1,start_date,end_date)all_profit
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| net_value | net_value_timing | win_rate | profit_ratio | |
|---|---|---|---|---|
| 2019-01 | 0.97561 | 4.052007 | 0.717949 | 4.153306 |

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程







