华泰风险收益一致性择时模型¶
研究目的¶
本文参考华泰证券《华泰风险收益一致性择时模型》,采用研报内的方法对风险收益一致性进行研究。根据研报分析,当行业的收益率与其贝塔呈现较好的正相关时,可以认为市场收益率为正,市场处于上涨状态;当行业的收益率与其贝塔呈现负相关时,可以认为市场收益率为负,市场处于下跌状态,利用这种关系即可构造择时模型。这是华泰风险收益一致性择时的基本思想。
根据此结论,本文试图对研报里面的结果进行了复现并分析,并对风险收益一致性进行了研究,从而其构建择时信号。另外,本文还试图将风险收益一致性信号与均线信号相结合,探究均线策略能否进一步改善风险收益一致性策略。
研究思路¶
自从20世纪50年代资本资产定价模型提出之后,人们习惯使用贝塔来代表资产与市场组合之间的关系。根据资本资产定价模型,假设资产的贝塔值是稳定的,那么在市场上涨的时候,贝塔高的资产应该收获更高的收益,但是市场下跌的时候也会承担更多的损失,所以贝塔值代表了资产承担市场风险的大小。通过资本资产定价模型我们找到了市场中存在的一种结构,不同资产的涨跌幅与市场组合的涨跌幅会存在相对固定的对应关系。如果反 过来使用这种对应关系,就得到了一种观察市场的方法,比如当发现高贝塔的资产收益较高,低贝塔的资产收益较低时,那市场大概率处于一种上升状态,当发现高贝塔的资产收益较低,低贝塔的资产收益较高时,市场可能处于一种下跌状态,如此我们可以构造一个择时模型。
贝塔是一项资产或投资组合对市场投资组合方差 的贡献程度,也即该资产或组合相对于市场波动性的敏感程度。贝塔越高,表明该资产或 组合受市场波动的影响越大,从而带来更大的风险溢价(即$β_p(R_m-R_f)$,括号内的部分为市场风险溢价)。在市场上涨(或下跌)时,高贝塔的资产由于承担了更多的市场风险, 其收益的变动会比低贝塔的资产更为剧烈。
在资本资产定价模型的收益率公式中,如果贝塔是固定的,那资本的收益率主要取决于市场的收益率,所以市场上涨高贝塔行业涨幅更大,市场下跌同样高贝塔行业会下跌更多。借助于这一点,可以尝试逆向推断市场的涨跌,当行业涨幅与其贝塔状态基本一致的时候说明市场是上涨的,相反的时候说明市场是下跌的。
数据获取¶
研报中市场指数选用万得全A指数,行业指数选用中信一级行业指数。由于数据来源限制,此处行业指数我们选择申万一级行业指数,而市场指数选取国证全A指数。数据时间段为2005年2月3日至今,频率为周度。我们需要用指数的周收益率来计算beta。
#数据获取
from jqdata import *
import time,datetime
import numpy as np
import pandas as pd
from jqdata import finance
# #获取每周最后一个交易日的申万一级行业指数收盘价
industries_df = get_industries("sw_l1")
deprecated_industries = ['801060','801070','801090','801100','801190','801220']
industries = list(industries_df.index)
start_dates = list(industries_df['start_date'])
trade_days = get_trade_days(start_date='2005-02-03')
ret_dict={}
for code,start_date in zip(industries,start_dates):
if code in deprecated_industries:
continue
#国证A指在2005年2月3日后才有数据
start_date = trade_days[0]
q=query(finance.SW1_DAILY_PRICE).filter(finance.SW1_DAILY_PRICE.date>=start_date,finance.SW1_DAILY_PRICE.code==code)
df=finance.run_query(q)
if len(df)!=len(trade_days):
trade_days=trade_days[0:-1]
df_date=list(df['date'])
df_date_weekday =np.array([i.weekday() for i in df_date])
b=df_date_weekday[0:-1]-df_date_weekday[1:]
c=df['date']
close=np.array(df[0:-1][b!=-1]['close'])
ret = close[1:]/close[:-1]-1
ret_dict[code]=ret
ret_dict['date'] = df[0:-1][b!=-1]['date'][1:]
#获取每周最后一个交易日的国证A指
mkt_index = get_price('399317.XSHE',start_date='2005-02-03',end_date=trade_days[-1],fields=['close'])
mkt_close = np.array(mkt_index[0:-1][b!=-1]['close'])
mkt_ret =mkt_close[1:]/mkt_close[0:-1]-1
ret_dict['mkt'] = mkt_ret
ret_df = pd.DataFrame(ret_dict)
ret_df.head(10)
不同行业的周期特征及beta表现¶
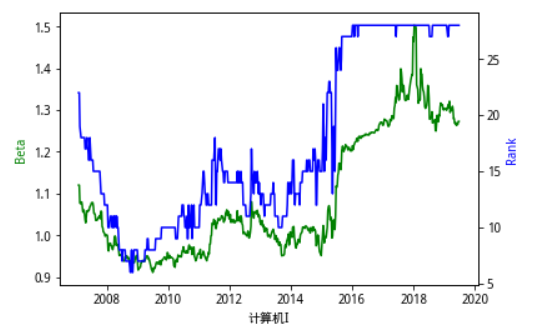
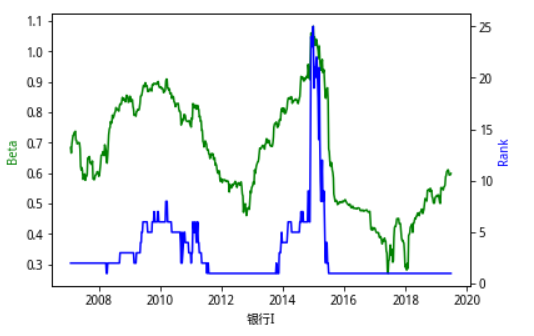
为了直观地感受不同行业Beta值地周期特征,我们将行业贝塔在每一个截面从小到大排序,得到行业贝塔的秩次,用 rank 表示。将行业贝塔rank在同一张图中表示出来,得到下面这一系列的图。总的来看,行业beta值比较稳定,但在某些特殊时刻也存在跃迁 式的变化。例如 15 年中期,急剧的上涨行情使很多行业的贝塔发生了变化,而且这种变化也延续至今。偏向于 TMT类型的行业,计算机、传媒、电子、通信、电力设备等在15年5、6月份贝塔值急剧上升,转变为高贝塔类行业,而银行、非银等行业贝塔值快速下降,行业特性向低贝塔靠近,在此之后,行业的贝塔值在16年一直处于比较稳定的状态。
import statsmodels.api as sm
#用N周的数据计算Beta,第N周开始有beta,研报中N为98
#获取行业中文名称
ind_df=get_industries('sw_l1')
ind = ind_df.index
valid_ind = list(set(ind)^set(deprecated_industries))
valid_ind_df = ind_df.loc[valid_ind]
ind_dict = dict(zip(valid_ind_df.index,valid_ind_df['name']))
#计算行业beta
N=98
beta_dict = {}
beta_dict['date'] = ret_dict['date'][N-1:]
for k,ret in ret_dict.items():
if k!='date'and k!='mkt':
beta_series = []
for i in range(len(ret)-N+1):
x = sm.add_constant(mkt_ret[i:i+N])
model = sm.OLS(ret[i:i+N],x)
results = model.fit()
beta_series.append(results.params[1])
beta_dict[k] = beta_series
beta_df = pd.DataFrame(beta_dict)
date = beta_df['date']
beta_df_t = beta_df.T
beta_rank=beta_df_t.iloc[1:].rank().T
plt.figure()
for i in range(1,29):
print(i)
#plt.subplot(28,1,i)
plt.figure(figsize=(10,8))
code = beta_df.columns[i]
x = beta_dict['date']
y1 = beta_dict[code]
y2 = beta_rank[code]
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax1.plot(x,y1,'g-')
ax2.plot(x,y2,'b-')
ax1.set_xlabel(ind_dict[code])
ax1.set_ylabel("Beta",color='g')
ax2.set_ylabel("Rank",color='b')
plt.show()




























信号生成和择时体系构建¶
接下来我们利用行业的贝塔与其收益率之间的关系构建择时模型,由于贝塔代表行业相比于市场组合的风险承担,本质上也代表行业相对于市场组合的杠杆率,一定程度上度量了风险,所以将择时模型起名为风险收益一致性择时模型。
如前所述,资产的贝塔大小与资产收益变动幅度存在相关性,而各个行业具有特征明显且相对稳定的贝塔。基于这一性质,我们可以对行业的贝塔与收益进行观测,进而对判断市场的运行状况:
1、当贝塔与收益趋于一致,即高贝塔的行业收益更高时,认为市场表现良好,观点看多;
2、当贝塔与收益呈反向关系,即高贝塔的行业收益更低时,认为市场表现不佳,观点看空。这一策略有着清晰的逻辑,并且以行业与市场指数做比较,在长期看较为稳定,适合对市 场进行长期判断。
为了度量行业贝塔与收益的一致性,我们引入Spearman 秩相关系数作为工具。
我们利用Spearman秩相关系数度量行业Beta与收益的一致性。
利用之前两年左右的数据,我们在每周末可以得到28个行业的Beta。得到Beta后,我们计算行业Beta与行业收益率的秩相关系数。在计算时,我们假设行业贝塔在周中保持静态不变,采用29个行业当周的收益率$r_t$与上周的贝塔 $β_{t-1} $进行计算。这样的好处是贝塔中并没有包含本周的收益率信息,两者保持一定意义上的相对独立,防止某个异常值带来的贝塔偏离。
为了过滤相关系数中的噪音,得到更稳定的长周期择时信号,我们对秩相关系数取4周的滑动平均,得到滑动平均序列 𝜌̅𝑠。
根据研报,我们选取98周数据计算β,秩相关系数选取0.128作为阈值。当𝜌̅𝑠>0.128时,发出一次买入信号;当𝜌̅𝑠<-0.128时,发出一次卖出信号。若连续发出两次同向信号,则执行买入/卖出操作。
从信号发出的时间来看,使用不同的行业指数对于信号发出还是有些影响的。总的来说,使用申万行业一级指数和研报中阈值的结果不佳,年化收益过低,不能跑赢国证A指。
from scipy.stats import spearmanr
threshold=0.128
#threshold为阈值,print_order为是否打印买卖指令
def back_test(threshold,print_order=True):
corr_list =[]
#第t周收益与t-1周的beta
for i in range(len(beta_df)-1):
corr_list.append(spearmanr(beta_df.iloc[i][1:].astype(float),ret_df.iloc[i+N][:-2].astype(float))[0])
corr_dict={}
corr_dict['date']=beta_df['date'][1:]
corr_dict['corr']=corr_list
corr_df=pd.DataFrame(corr_dict)
corr_df['ma_4'] = corr_df['corr'].rolling(window=4,min_periods=1).mean()
corr_df['signal']=0
corr_df['signal'][corr_df['ma_4']>threshold]=1
corr_df['signal'][corr_df['ma_4']<-threshold]=-1
position_list = [0]
flag=0
order_dict = {'date':[],'指令':[]}
for i in range(1,len(corr_df['signal'])):
if flag==0:
if np.array(corr_df['signal'])[i-1]==1 and np.array(corr_df['signal'])[i]==1:
position_list.append(1)
flag=1
order_dict['date'].append(corr_df['date'].iloc[i])
order_dict['指令'].append('买入')
else:
position_list.append(0)
elif flag==1:
if np.array(corr_df['signal'])[i-1]==-1 and np.array(corr_df['signal'])[i]==-1:
position_list.append(0)
flag=0
order_dict['date'].append(corr_df['date'].iloc[i])
order_dict['指令'].append('卖出')
else:
position_list.append(1)
order_df = pd.DataFrame(order_dict)
if print_order:
print(order_df)
corr_df['position']=position_list
corr_df['ret']=0
corr_df['ret'].iloc[1:] = np.array(ret_df['mkt'])[N+1:]*np.array(corr_df['position'])[:-1]
ret = list(corr_df['ret'])
cum_ret=[]
for i in range(len(ret)):
if i==0:
cum_ret.append(1+ret[i])
else:
cum_ret.append((1+ret[i])*cum_ret[i-1])
corr_df['cum_ret']=cum_ret
return corr_df
corr_df=back_test(threshold)
#计算各项指标,一年按50周计算
max_cum_ret=[]
cum_ret = np.array(corr_df['cum_ret'])
for i in range(len(cum_ret)):
max_cum_ret.append(max(cum_ret[:i+1]))
drawdown=1-corr_df['cum_ret']/max_cum_ret
annual_ret = corr_df['cum_ret'].iloc[-1]**(1*50/len(corr_df))-1
vol = corr_df['ret'].std()*np.sqrt(50)
mdd = max(drawdown)
sharpe = annual_ret/vol
summary_df = pd.DataFrame({'年化收益':[annual_ret],'年化波动率':[vol],'最大回撤':[mdd],'夏普比率':[sharpe]})
print(summary_df)
#作图
plt.figure(figsize=(15,6))
mkt_index = get_price('399317.XSHE',start_date='2005-02-03',end_date=trade_days[-1],fields=['close'])
data=corr_df.set_index('date')
combination=data.join(mkt_index)
plt.plot(combination.index,combination['cum_ret'])
plt.plot(combination.index,combination['close']/combination['close'].iloc[0])
plt.show()

敏感性分析¶
从上面的回测可以看出,应用原始阈值的择时策略效果不佳。而Spearman 秩相关系数的计算较为敏感,其假设检验的拒绝域需要精确到千分位,应用 Spearman 方法的本策略不可避免地受到这一敏感性的影响。所以,我们需要对敏感性进行分析,找出最佳阈值。敏感性分析的参数为信号触发阈值,选取0.100-0.300(步长为0.001)进行测试,选取夏普比率作为优化目标,样本内夏普比率的变动如下:
thresholds=np.array(range(100,301,1))/1000
sharpe_dict={'阈值':[],'夏普比率':[]}
for threshold in thresholds:
corr_df=back_test(threshold,print_order=False)
annual_ret = corr_df['cum_ret'].iloc[-1]**(1*50/len(corr_df))-1
vol = corr_df['ret'].std()*np.sqrt(50)
sharpe = annual_ret/vol
sharpe_dict['阈值'].append(threshold)
sharpe_dict['夏普比率'].append(sharpe)
sharpe_df = pd.DataFrame(sharpe_dict)
plt.figure(figsize=(20,10))
plt.plot(sharpe_df["阈值"],sharpe_df['夏普比率'])
plt.show()

根据敏感性分析,我们可知最优阈值为0.142。此时夏普率为0.64,且策略回撤大幅减少,能够跑赢市场指数。
corr_df=back_test(0.142)
#计算各项指标,一年按50周计算
max_cum_ret=[]
cum_ret = np.array(corr_df['cum_ret'])
for i in range(len(cum_ret)):
max_cum_ret.append(max(cum_ret[:i+1]))
drawdown=1-corr_df['cum_ret']/max_cum_ret
annual_ret = corr_df['cum_ret'].iloc[-1]**(1*50/len(corr_df))-1
vol = corr_df['ret'].std()*np.sqrt(50)
mdd = max(drawdown)
sharpe = annual_ret/vol
summary_df = pd.DataFrame({'年化收益':[annual_ret],'年化波动率':[vol],'最大回撤':[mdd],'夏普比率':[sharpe]})
print(summary_df)
#作图
plt.figure(figsize=(15,6))
data=corr_df.set_index('date')
combination=data.join(mkt_index)
plt.plot(combination.index,combination['cum_ret'])
plt.plot(combination.index,combination['close']/combination['close'].iloc[0])
plt.show()
corr_df.to_excel('0.142.xlsx')

与均线策略的结合¶
纯多策略在 15 年的下跌中出现了一个巨大的回撤。另外,择时模型给出的信号为周频信号,为了将信号扩展到日频,可以尝试加入均线。
具体做法为计算市场指数当周收盘价与20日均线之差,若差值为正,均线上给出看多信号;若差值为负,均线上给出看空信号。当均线上信号与策略择时信号一致时进行操作买入或卖出,当信号不一致时清仓,既不做多也不做空。
加入均线策略后,由于均线策略的延迟特性,组合策略未能避过2016年左右的回撤,导致年化收益和夏普率均下降。
def combination_back_test(threshold,print_order=True):
#生成均线信号
corr_list =[]
#第t周收益与t-1周的beta
for i in range(len(beta_df)-1):
corr_list.append(spearmanr(beta_df.iloc[i][1:].astype(float),ret_df.iloc[i+N][:-2].astype(float))[0])
corr_dict={}
corr_dict['date']=beta_df['date'][1:]
corr_dict['corr']=corr_list
corr_df=pd.DataFrame(corr_dict)
corr_df['ma_4'] = corr_df['corr'].rolling(window=4,min_periods=1).mean()
corr_df['signal']=0
corr_df['signal'][corr_df['ma_4']>threshold]=1
corr_df['signal'][corr_df['ma_4']<-threshold]=-1
mkt_index = get_price('399317.XSHE',start_date='2005-02-03',end_date=trade_days[-1],fields=['close'])
mkt_index['ma_20'] = mkt_index.rolling(window=20).mean()
data=corr_df.set_index('date',drop=False)
combination=data.join(mkt_index)
combination['ma_signal']=(combination['close']>combination['ma_20']).astype(int)
position_list = [0]
flag=0
order_dict = {'date':[],'指令':[]}
for i in range(1,len(corr_df['signal'])):
if flag==0:
if np.array(combination['signal'])[i-1]==1 and np.array(combination['signal'])[i]==1:
if np.array(combination['ma_signal'])[i]==1:
position_list.append(1)
flag=1
order_dict['date'].append(combination['date'].iloc[i])
order_dict['指令'].append('买入')
else:
position_list.append(0)
else:
position_list.append(0)
elif flag==1:
if np.array(combination['signal'])[i-1]==-1 and np.array(combination['signal'])[i]==-1:
if np.array(combination['ma_signal'])[i]==0:
position_list.append(0)
flag=0
order_dict['date'].append(combination['date'].iloc[i])
order_dict['指令'].append('卖出')
else:
position_list.append(1)
else:
position_list.append(1)
if print_order:
order_df = pd.DataFrame(order_dict)
print(order_df)
combination['position']=position_list
combination['ret']=0
combination['ret'].iloc[1:] = np.array(ret_df['mkt'])[N+1:]*np.array(combination['position'])[:-1]
ret = list(combination['ret'])
cum_ret=[]
for i in range(len(ret)):
if i==0:
cum_ret.append(1+ret[i])
else:
cum_ret.append((1+ret[i])*cum_ret[i-1])
combination['cum_ret']=cum_ret
return combination
combination = combination_back_test(0.142)
#计算各项指标,一年按50周计算
max_cum_ret=[]
cum_ret = np.array(combination['cum_ret'])
for i in range(len(cum_ret)):
max_cum_ret.append(max(cum_ret[:i+1]))
drawdown=1-combination['cum_ret']/max_cum_ret
annual_ret = combination['cum_ret'].iloc[-1]**(1*50/len(combination))-1
vol = combination['ret'].std()*np.sqrt(50)
mdd = max(drawdown)
sharpe = annual_ret/vol
summary_df = pd.DataFrame({'年化收益':[annual_ret],'年化波动率':[vol],'最大回撤':[mdd],'夏普比率':[sharpe]})
print(summary_df)
#作图
plt.figure(figsize=(15,6))
#mkt_index = get_price('399317.XSHE',start_date='2005-02-03',end_date=trade_days[-1],fields=['close'])
#data=combination.set_index('date')
#combination=data.join(mkt_index)
plt.plot(combination.index,combination['cum_ret'])
plt.plot(combination.index,combination['close']/combination['close'].iloc[0])
plt.show()

combination
风险收益一致性与均线结合策略的敏感性分析¶
与之前类似,我们对结合策略进行参数敏感性分析。
thresholds=np.array(range(100,301,1))/1000
sharpe_dict={'阈值':[],'夏普比率':[]}
for threshold in thresholds:
corr_df=combination_back_test(threshold,print_order=False)
annual_ret = corr_df['cum_ret'].iloc[-1]**(1*50/len(corr_df))-1
vol = corr_df['ret'].std()*np.sqrt(50)
sharpe = annual_ret/vol
sharpe_dict['阈值'].append(threshold)
sharpe_dict['夏普比率'].append(sharpe)
sharpe_df = pd.DataFrame(sharpe_dict)
plt.figure(figsize=(20,10))
plt.plot(sharpe_df["阈值"],sharpe_df['夏普比率'])
plt.show()

最优阈值为0.127-0.13,但夏普率仅为0.54,未能战胜原始策略。
研究结论¶
总的来说,风险收益一致性模型可以跑赢市场,收益也比较稳定,但在2015年中遭遇了大回撤。策略的大回撤主要来源于 15 年年中的急速下跌,这段时期各行业的贝塔值也发生了急剧 变化,因此导致信号出现了滞后与偏差,这是模型的主要风险,即市场风格的急剧变化。
我们试图加入简单均线策略来改善模型的表现。但由于均线策略的延迟性,策略没能避开15年底的反转带来的大回撤,表现并不如原始模型。
市场风格的变化不单单对此模型,对大部分策略都有很强的破坏性。因为模型总是基于市 场中已经存在的某种固有模式进行建模,当模式迅速切换时,模型很难及时反映。这也从另一方面证明了长期稳定策略的稀缺性。若想改善模型回撤,一个可以考虑的角度是增加 交易频率,甚至在日内做一些操作,放弃部分收益来降低波动与回撤,但这也势必带来交易成本的提高。









