前几天看到一篇市场底部特征研究的文章【华创金工】,觉得有点意思,下面就是将这些衡量底部特征的内容在研究里进行实现。
文章的核心逻辑如下所述:
- 低价股比例:逻辑是牛市消灭仙股,熊市产生仙股
- 破净股比例:打折促销,领先指标。
- M2/总市值中位数:相当于每一元的市值,有多少M2支撑和刺激?可以理解为“施肥率”。
- PE中位数和十年国债收益率倒数:比较股票和国债收益率的高低,经典的股债轮动指标。
- 全市交易额有没有触底?全市场人气。
- 个股流动性有没有触底?大底中大部分个股流动性枯竭。
- 区间最大跌幅的中位数: 大底是跌出来的,大底的水准是高点腰斩,在腰斩。
- 人气指标:次新股的破发率。
- 除了全市场的估值低,各个行业也一片惨淡,几无例外。
大底的九个衡量维度具体介绍
- 熊市时泥沙俱下,牛市时鸡犬升天,市场总是在恐惧和疯狂的情绪中起起落落落落落......大家都知道高抛低吸,低买高卖是股市操作的致胜秘籍,问题就在于市场什么时候会迎来转折的时机。
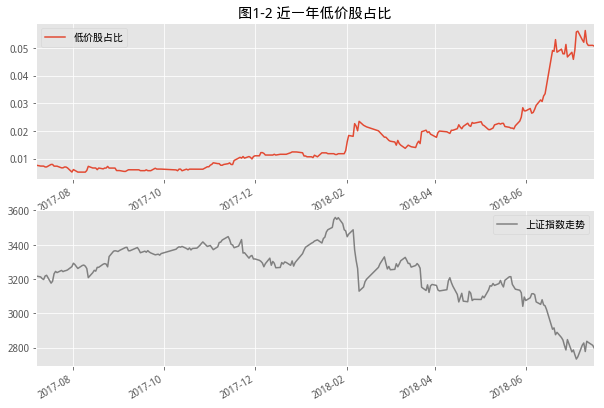
1. 低价股比例
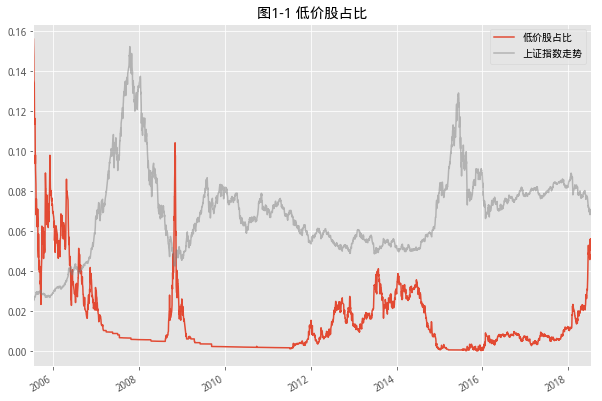
- 牛市消灭仙股,熊市产生仙股,仙股原意是指价格已经低于1元的股票,这里放大了仙股价格区间,设定为小于2元的股票,统计了从07年开始,低价股数量占比的时间序列。可是,考虑到时间跨度超过10年,那是当年可以买碗牛肉拉面的两块钱,为了抵消通货膨胀的影响,所以这里做了些改动,将条件按每年4%的无风险收益进行增长,到目前,这个低价格的阈值已经是3.2元。
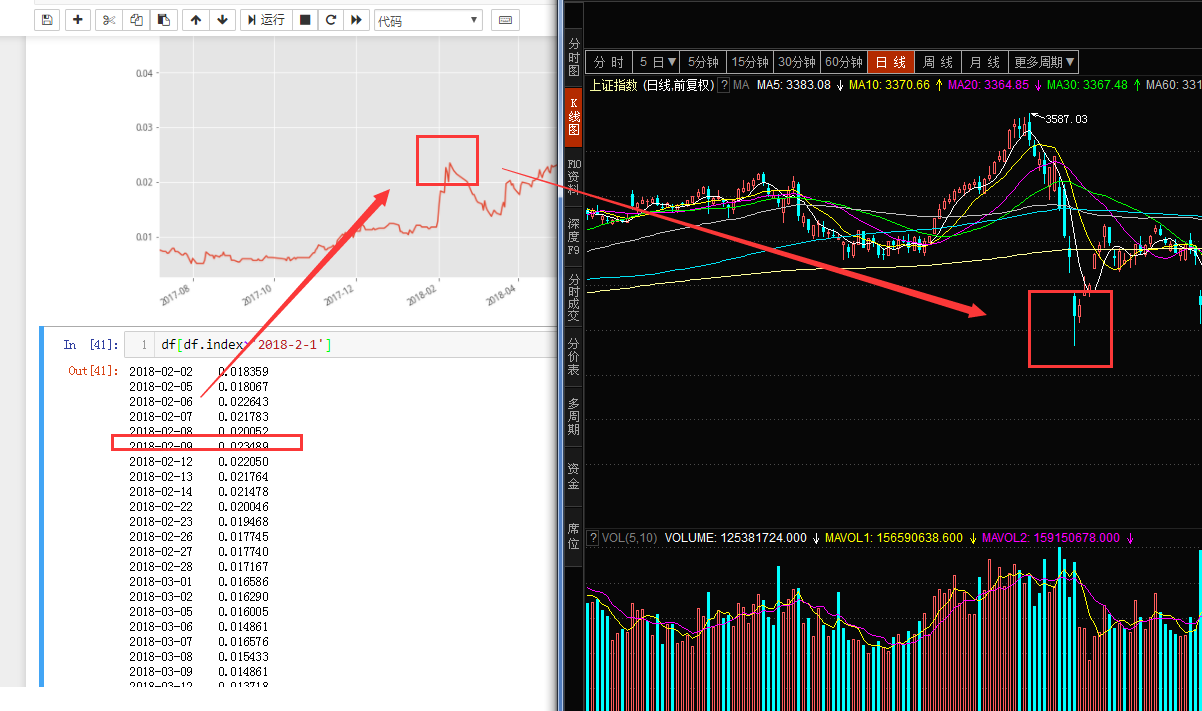
- 目前看到的几个拐点基本上都是和市场的拐点同步,这里讲最近一次的拐点放大看到如下情况
#返回股价低于2元的股票个数占比 def f1(self,date_list): bei = len(date_list)//13 se_price_2 = [] for i in range(1,13): e = date_list[i*bei] s = date_list[(i-1)*bei] if i == 0: s = date_list[0] elif i == 12: e = date_list[-1] all_stock = list(get_all_securities(types='stock',date=e).index) def f1_1(x): x=x.dropna(axis=0) return sum(x) df = get_price(all_stock,start_date=s,end_date=e,fields=['close'],fq=None)['close'] df_1 = df<=2*(1.04)**i #print(2*(1.04)**i) se1 = df_1.apply(f1_1,axis=1) l2 = [len(get_all_securities(types='stock',date=i)) for i in se1.index ] se2 = pd.Series(l2,index=se1.index) #se2 = df_1.apply(f1_1[1],axis=1) se_price_2.append(se1/se2) return pd.concat(se_price_2)
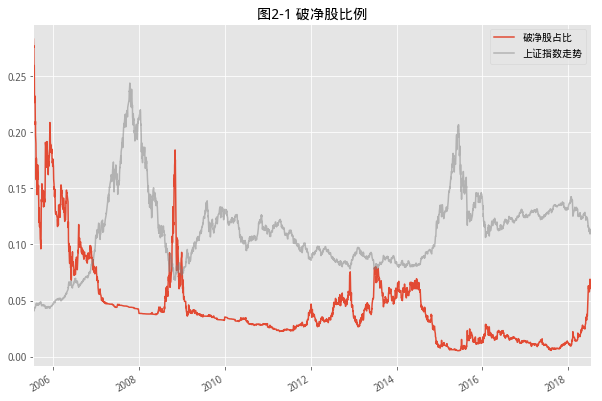
2. 破净股比例
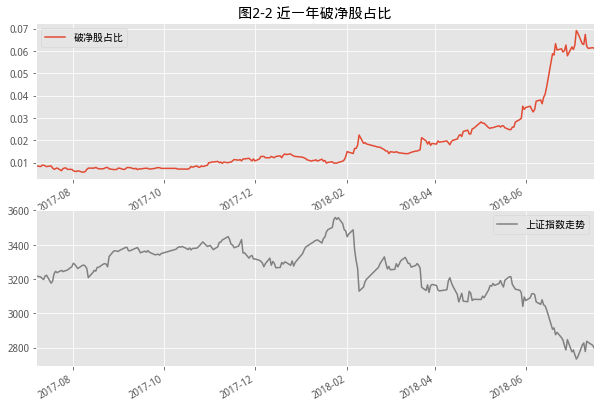
- 破净是指股价跌破净资产值,破净股具体就是指股票的每股市场价格低于它每股净资产价格,破净的特点和逻辑,和低价股类似。这一点从下面的图中看确实如此,从历史走势来看,破净股数据的变化情况,与股票市场的顶底区域是同步的。针对这个问题,我们找出市场中对应的几个位置特别位置和该指标数据进行对比,这里是2018年2月9号的具体表现
- 具体来看,2017年年底以来该比例骤然上升,从0.57%到目前达到6.1%的水平,接近2014年底部的比例。
#返回破净股比例 def f2(self,date_list): pb = [] for d in date_list: df_temp = get_fundamentals(query(valuation.code,valuation.pb_ratio,valuation.circulating_market_cap,valuation.pe_ratio),date=d) a = len(df_temp) b = len(df_temp[df_temp['pb_ratio']<=1]) #b = len(df_temp[(df_temp['pb_ratio']<=1)&(df_temp['pb_ratio']>=0)]) pb.append(b/a) df_2 = pd.DataFrame(pb,index=date_list,columns=['pb_ratio']) return df_2['pb_ratio']
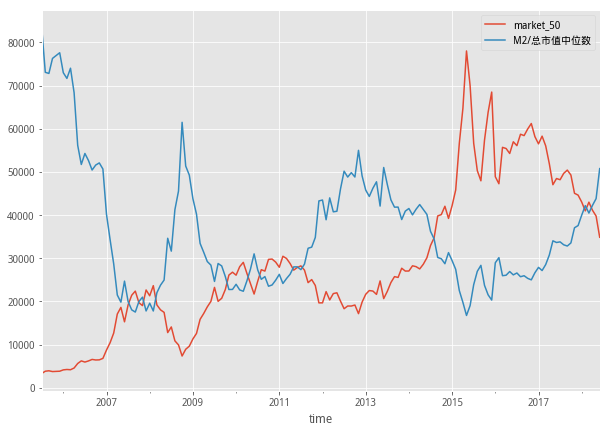
3. M2/总市值中位数
- 先来看下什么是M2:
M2(广义货币)= 流通中的现金(即流通于银行体系之外的现金) 企业活期存款 准货币(定期存款 居民储蓄存款 其他存款 证券公司客户保证金)
简单粗暴的来讲就是指现金 活期存款 定期存款,M2越大越有钱,有了钱就可以大胆的买买买了,买酒、买药、买榨菜、买面条......M2被比作市场的肥料,这里将M2/总市值中位数进行了指标构建,相当于每平方米的施肥率。而选择中位数却不用总市值,是想弱化权重股对这个指标的过度影响,这里也是可以理解,毕竟中小盘股的参与度要高于超级大盘股。
图中已经可以看到目前指标值已经逼近之前高点注意这里市值数据为了和M2数据在同一个图中对比做了缩放
def f3_1(self,date_list): M2_date = pd.read_excel('M2.xls') M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])] M2_date.index = M2_date['time'].values date_list_new = M2_date.time market = [] for d in date_list_new: df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d) c = df_temp['circulating_market_cap'].quantile(0.5) market.append(c) df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%']) df_3['m2'] = M2_date['M2'] df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%'] df_3 = df_3.sort_index(ascending=1) return df_3#['M2/总市值中位数']国债和M2数据 链接: https://pan.baidu.com/s/11RMzo7RjXRj5FJ4Gind6ow 密码: 2dwk
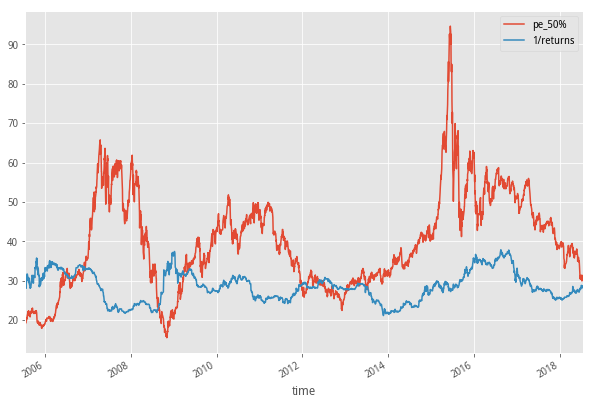
4. PE中位数和十年国债收益率倒数的比较
- 先说说国债收益率和股市的关系,国债作为固收类产品,其收益率就是我们常说的无风险收益率,稳赚不赔,国债收益率较高的时候,会吸引资金 从高风险领域不断流入低风险的国债,造成流动性紧张,其他资产价格就会下跌;国债利率低,就会导致更多资金流入高风险领域,如间接持有股票型基金,或直接入市等,导致市场热度上升,这就是股债轮动存在的依据。
- 下图就是市场PE中位数和十年国债收益率倒数的走势情况。
- “第一、就是PE中位数随着小盘股占比越来越高,PE中位数也水涨船高。现在的PE中位数和08年PE中位数,内涵已经差了很多。”
目前,看到PE中位数已经接近前低,假设PE是以线性增长的话很明显已经跌破了之前两次低点的连线,PE中位数和国债收益倒数非常接近,但还未产生交叉 - “第二、蓝色线和灰色线的交叉,注意,通常不止一次。”
前几次的数据曲线中我们看到,红线(PE中位数)几次下跌都是在熊市中下穿蓝线(10年国债收益率倒数),在市场回暖的过程中红线势必突破蓝线,我们可以看到一轮完整的牛熊市切换貌似都要触及一次蓝线,构成市场的左侧信息和右侧信号,中间即是买票上车的时间。#PE中位数和十年国债收益率倒数的比较 def f4_1(self,date_list): deb_date = pd.read_excel('10年国债数据.xls') deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])] deb_date.index = deb_date['time'].values date_list_new = deb_date.time pe = [] cir_market_ratio = [] for d in date_list_new: df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d) a = len(df_temp) b = len(df_temp[df_temp['circulating_market_cap']<45]) #print(df_temp['circulating_market_cap'].quantile(0.5)) c = df_temp['pe_ratio'].quantile(0.5) cir_market_ratio.append(b/a) pe.append(c) df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%']) df_4['returns'] = deb_date['returns'] df_4['1/returns'] = 100/deb_date['returns'] df_4['cir_market_ratio'] = cir_market_ratio #df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns'] return df_4[['pe_50%','1/returns','cir_market_ratio']]
- “第一、就是PE中位数随着小盘股占比越来越高,PE中位数也水涨船高。现在的PE中位数和08年PE中位数,内涵已经差了很多。”
5. 全市场成交额
- “大底时全市成交额,是高点全市成交额的10%。目前已经符合大底的标准。”
下面的图是将沪深两市每日成交额进行合计,惊奇的发现,2015年市场成交额数据竟然如此高不可攀,直逼2万亿,达到所有历史行情之最,让人不得不感慨这2015年杠杆牛的威力,明处券商两融业务做得风生水起,暗处场外配资遍地开花。虽然点数没有突破历史,但是成交金额却创下了历史记录。
将近几年的成交额数据放大,可以发现近期成交额基本处于15年以来成交额2千多万的底线水平,占最高点成交额的11%
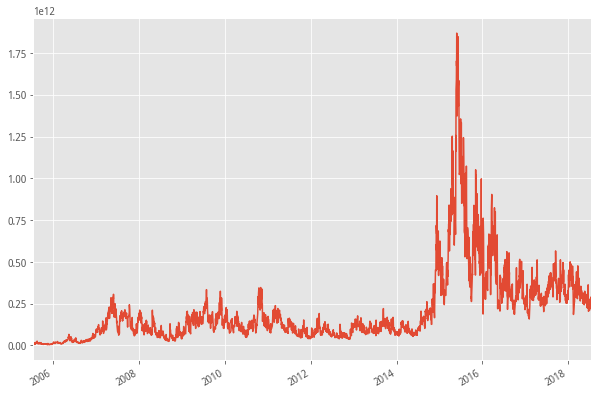
#全市场成交额
#输出两个市场成交额数据变化
def f5(self,date_list):
s,e = date_list[0],date_list[-1]
pl = get_price(['399001.XSHE','000001.XSHG'],start_date=s,end_date=e,fields=['money'])['money']
pl['money'] = pl['399001.XSHE'] pl['000001.XSHG']
return pl['money']
6. 个图成交冷淡
- 市场整体热度不够,个股自然不会好到哪里。目前从图中看到,个股的成交已经是在上次股灾值附近。
- 这里以100万/天的成交额作为判断标准,来衡量市场个股是否冷淡。同样,由于时间跨度较大,也要考虑到市场整体的上涨对该判断带来的影响,不过这里是以M2增速的标准进行处理,我们也参考这个标准进行处理:
M2在2005年6月底数据为275,785.53,到2018年6月底数据为1,770,200.00,按复利增长计算,基本上是每年14%的速度上升,将该速度套用在2008年每天100万成交额的基础上,得出了2018年418万成交额的条件。图中看到貌似目前还未能满足该条件,未做比例统计#个股成交的冷淡 #返回个股成交金额 def f6(self,date_list): l_money_mean = [] for i in date_list: all_stock = list(get_all_securities(types='stock',date=i).index) df_money = get_price(all_stock,end_date=i,count=1)['money'] df_money = df_money.dropna(axis=1) money_mean = sum(df_money.T)/df_money.shape[1] l_money_mean.append(money_mean.values) df_money_mean = pd.DataFrame(l_money_mean,index=date_list,columns=['money_mean']) return df_money_mean
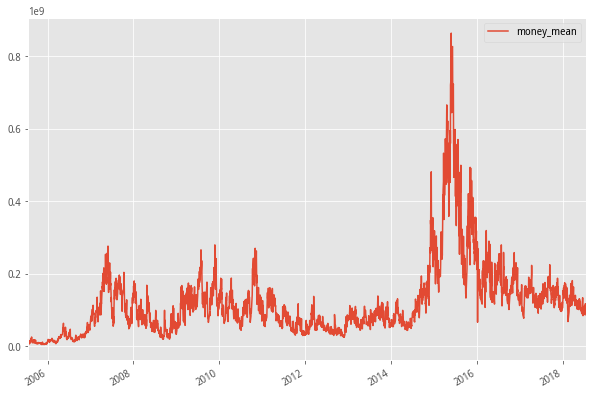
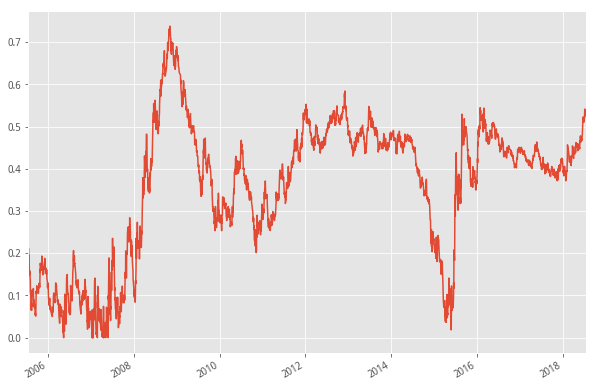
7. 个股区间最大跌幅中位数
- 下面的图是沪深300的成分股最大回撤中位数数据,可以看到,在2008年创下了最高纪录73%,与原文提到的74.44%相当接近,2014年牛市启动之前曾达到58%,最近的一次高点,也就是在2016年2月股灾2.0时,该数据达到了54.48%,而现在该值在54%左右徘徊,已经符合该底部特征的条件。
#个股区间最大跌幅中位数 def f7(self,date_list): date = date_list[-1] #all_stock = list(get_all_securities(types='stock',date=date).index) all_stock = get_index_stocks('000300.XSHG') df_temp = get_price(all_stock,start_date='2005-4-1',end_date=date,fields=['close'])['close'] se_l = [] for i in date_list: df_temp_1 = df_temp[df_temp.index<i] #回撤 se = 1-df_temp_1[-1:]/df_temp_1.max() #格式为series se_l.append(se.T.quantile(0.5)) return pd.concat(se_l)
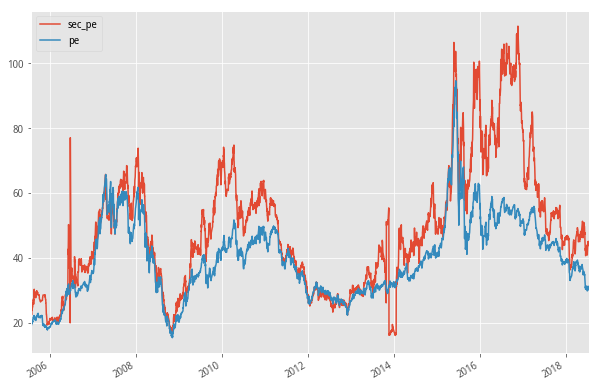
8. 次新股的破发率
次新股,一般是指上市一年以内的股票,可以通过以下代码获取近一年上市的所有股票,共计241只,占全市场股票6.8%,取出全市场换手率最高的前100只股票,其中次新股却有57只,对广大股民来讲,次新确实有着绝对的人气。
import datetime #获取所有的股票信息 df = get_all_securities() #筛选出近一年的股票 df[df['start_date']>datetime.date(2017,7,20)]下面是次新股和全市场股票的PE中位数的数据,就最近一次的牛市行情来看,次新是不一样的,在2015股灾之后,依然走出了一波行情,直到2016年年底才开始跳水,这与IPO加速都有着直接的关系。数据往前推几年,牛熊交替的过程中我们看到,市场好的时候,大家各有各的花样,市场不好的时候,看起来都是一个样。最低点时次新股与全市场估值接近,就是所谓通杀。就目前来看,次新还是有着自己的想法。
#获取次新股和全市场股票的PE中位数 def f8(self,date_list): sec_new_pe = [] pe = [] p_ratio_l = [] all_stock = get_all_securities(types='stock',date=date_list[-1]) all_stock['fir_open'] = [get_price(stock,end_date=all_stock.loc[stock]['start_date'],count=1,fields=['open'])['open'].values[0] for stock in all_stock.index] for d in date_list: df_temp = get_price('000001.XSHG',end_date=d,count=252) year_1,month_1,day_1 = int(str(df_temp.index[0])[:4]), int(str(df_temp.index[0])[5:7]), int(str(df_temp.index[0])[8:10]) year,month,day = int(str(df_temp.index[-1])[:4]), int(str(df_temp.index[-1])[5:7]), int(str(df_temp.index[-1])[8:10]) sec_new_stock_df = all_stock[(all_stock['start_date']>datetime.date(year_1,month_1,day_1)) & (all_stock['start_date']<datetime.date(year,month,day))] sec_new_stock = sec_new_stock_df.index df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(sec_new_stock)),date=d) df_temp_1 = get_fundamentals(query(valuation.code,valuation.pe_ratio),date=d) pe_sec = df_temp['pe_ratio'].quantile(0.5) pe_all = df_temp_1['pe_ratio'].quantile(0.5) sec_new_pe.append(pe_sec) pe.append(pe_all) #获取次新股当前价格 sec_new_price = get_price(list(sec_new_stock),end_date=d,fields=['close'],count=1)['close'].T sec_new_price.columns=['fir_open'] p_ratio = sec_new_price['fir_open']/all_stock.loc[sec_new_price.index,:]['fir_open'] po_ratio = len(p_ratio[p_ratio<1])/len(p_ratio) p_ratio_l.append(po_ratio) df_pe = pd.DataFrame(sec_new_pe,index=date_list,columns=['sec_pe']) df_pe['pe'] = pe df_pe['p_ratio'] = p_ratio_l return df_pe
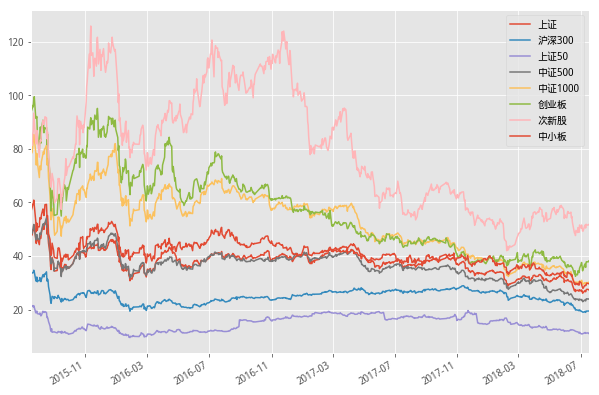
9. 市场大底,行业一片惨淡,无一例外
- 关于股票估值有很多的说法,就结果而言,至少到目前为止并没有一个可靠的办法,都是试图无限接近真实价值,但是结果本身甚至都不具收敛性,只能是挖掘相对好一点的方法。
- 比较常见的方法会以每股收益为基础,估计价格,以股票当前的价格比上每股收益,得出市盈率,其中每股收益是公司本身决定的,是个确定的值,而股票价格,就是参与者来决定的随机值,根据经验,我们可以找出历史的PE值在牛熊市、特定行业中的表现,pe = p/e转换为p=pe*e,从而得到估计的值,对当前价格进行指导。
- 在熊市的时候,大部分行业集中低估,行业估值的80%分位数,和全市场估值水平差不多。这一特征,这里并没有进行详细的数据演示,下面展示的是不同市值、不同板块的指数成分股50%分位数的时间序列,行业的话可以参考前面的代码,把股票池更换成行业成分股即可,调整下中位数刻度,进行对比验证了。
a = f() #由于部分指数上市较晚,这里开始时间从2015年开始 date_list = a.get_tradeday_list('2015-7-17','2018-7-17') df9 = a.f9(date_list) df9 = df9.sort_index(ascending=1) df9.plot(figsize=(10,7))#市场大底,行业一片惨淡,无一例外 #行业PE估值 def f9(self,date_list): #指数用成分股,pe值做市值加权处理 index_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE'] index_name = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板'] pe_fin = [] for i in date_list: pe_index = [] for j in index_list: stock_list = get_index_stocks(j,i) df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(stock_list)),date=i) pe = df_temp['pe_ratio'].quantile(0.5) pe_index.append(pe) pe_fin.append(pe_index) pe_df = pd.DataFrame(pe_fin,index=date_list,columns=index_name) return pe_df
总结
- 整个做完之后,熊市底部特征指标,与之前的大熊市相比还是有些差距,但是,市场前段时间也毕竟不是大牛市与之匹配。以上内容对市场底部特征的一些现象描述,仅是同步指标的话,只能是当做验证、防御的手段,最希望的还是能够从中挖掘出一些领先市场的指标方法,可以当做主动出击的武器。毕竟个人时间能力有限,还没有较为仔细验证哪些具备预测的功能。大家有兴趣可以提供思路或者意见,社区多多分享交流了,附上原文链接:https://mp.weixin.qq.com/s/sXGUJ3DXk_iIlsiVjXQ3Fg
多谢华创金工团队分享的文章及思路,大家共同学习了。整个过程获取数据和进行图表展示是基础,应该更多的关注目的和应用的方法,值得庆幸的是所有关于市场的宝贵经验,都能通过恰当的方式在聚宽平台上得以验证。
#导入各种包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
#方法
#获取交易日期列表
#时间序列函数
class f():
date_now = '2018-7-17'
all_stock_info = get_all_securities(types='stock',date=date_now)
all_stock = list(all_stock_info.index)
#df = get_price(list(all_stock.index),start_date='2008-01-01',end_date=date,fields=['close','money','volume'])['close']
#交易日期列表
def get_tradeday_list(self,s='2017-1-1',e=date_now,count=None):
if count != None:
df = get_price('000001.XSHG',end_date=e,count=count)
return df.index
else:
df = get_price('000001.XSHG',start_date=s,end_date=e)
return df.index
#股票个数序列
def all_stock_num(s,e):
get_all_securities(t)
#返回股价低于2元的股票个数占比
def f1(self,date_list):
bei = len(date_list)//13
se_price_2 = []
for i in range(1,13):
e = date_list[i*bei]
s = date_list[(i-1)*bei]
if i == 0:
s = date_list[0]
elif i == 12:
e = date_list[-1]
all_stock = list(get_all_securities(types='stock',date=e).index)
def f1_1(x):
x=x.dropna(axis=0)
return sum(x)
df = get_price(all_stock,start_date=s,end_date=e,fields=['close'],fq=None)['close']
df_1 = df<=2*(1.04)**i
#print(2*(1.04)**i)
se1 = df_1.apply(f1_1,axis=1)
l2 = [len(get_all_securities(types='stock',date=i)) for i in se1.index ]
se2 = pd.Series(l2,index=se1.index)
#se2 = df_1.apply(f1_1[1],axis=1)
se_price_2.append(se1/se2)
return pd.concat(se_price_2)
#返回破净股比例
def f2(self,date_list):
pb = []
for d in date_list:
df_temp = get_fundamentals(query(valuation.code,valuation.pb_ratio,valuation.circulating_market_cap,valuation.pe_ratio),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['pb_ratio']<=1])
#b = len(df_temp[(df_temp['pb_ratio']<=1)&(df_temp['pb_ratio']>=0)])
pb.append(b/a)
df_2 = pd.DataFrame(pb,index=date_list,columns=['pb_ratio'])
return df_2['pb_ratio']
#M2/总市值中位数
def f3(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
#M2/总市值中位数
def f3(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
def f3_1(self,date_list):
M2_date = pd.read_excel('M2.xls')
M2_date = M2_date[(M2_date['time']>date_list[0]) & (M2_date['time']<date_list[-1])]
M2_date.index = M2_date['time'].values
date_list_new = M2_date.time
market = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.circulating_market_cap),date=d)
c = df_temp['circulating_market_cap'].quantile(0.5)
market.append(c)
df_3 = pd.DataFrame(market,index=date_list_new,columns=['market_50%'])
df_3['m2'] = M2_date['M2']
df_3['M2/总市值中位数'] = df_3['m2']/df_3['market_50%']
df_3 = df_3.sort_index(ascending=1)
return df_3#['M2/总市值中位数']
#PE中位数和十年国债收益率倒数的比较
def f4(self,date_list):
deb_date = pd.read_excel('10年国债.xls')
deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])]
deb_date.index = deb_date['time'].values
date_list_new = deb_date.time
pe = []
cir_market_ratio = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['circulating_market_cap']<45])
#print(df_temp['circulating_market_cap'].quantile(0.5))
c = df_temp['pe_ratio'].quantile(0.5)
cir_market_ratio.append(b/a)
pe.append(c)
df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%'])
df_4['returns'] = deb_date['returns']
df_4['1/returns'] = 100/deb_date['returns']
df_4['cir_market_ratio'] = cir_market_ratio
#df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns']
return df_4[['pe_50%','1/returns','cir_market_ratio']]
#PE中位数和十年国债收益率倒数的比较
def f4_1(self,date_list):
deb_date = pd.read_excel('10年国债数据.xls')
deb_date = deb_date[(deb_date['time']>date_list[0]) & (deb_date['time']<date_list[-1])]
deb_date.index = deb_date['time'].values
date_list_new = deb_date.time
pe = []
cir_market_ratio = []
for d in date_list_new:
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio,valuation.circulating_market_cap),date=d)
a = len(df_temp)
b = len(df_temp[df_temp['circulating_market_cap']<45])
#print(df_temp['circulating_market_cap'].quantile(0.5))
c = df_temp['pe_ratio'].quantile(0.5)
cir_market_ratio.append(b/a)
pe.append(c)
df_4 = pd.DataFrame(pe,index=date_list_new,columns=['pe_50%'])
df_4['returns'] = deb_date['returns']
df_4['1/returns'] = 100/deb_date['returns']
df_4['cir_market_ratio'] = cir_market_ratio
#df_4['pe中位数/10年国债收益倒数'] = df_4['pe_50%']/df_4['1/returns']
return df_4[['pe_50%','1/returns','cir_market_ratio']]
#全市场成交额
#输出两个市场成交额数据变化
def f5(self,date_list):
s,e = date_list[0],date_list[-1]
pl = get_price(['399001.XSHE','000001.XSHG'],start_date=s,end_date=e,fields=['money'])['money']
pl['money'] = pl['399001.XSHE']+pl['000001.XSHG']
return pl['money']
#个股成交的冷淡
#返回个股成交金额
def f6(self,date_list):
l_money_mean = []
for i in date_list:
all_stock = list(get_all_securities(types='stock',date=i).index)
df_money = get_price(all_stock,end_date=i,count=1)['money']
df_money = df_money.dropna(axis=1)
money_mean = sum(df_money.T)/df_money.shape[1]
l_money_mean.append(money_mean.values)
df_money_mean = pd.DataFrame(l_money_mean,index=date_list,columns=['money_mean'])
return df_money_mean
#个股区间最大跌幅中位数
def f7(self,date_list):
date = date_list[-1]
#all_stock = list(get_all_securities(types='stock',date=date).index)
all_stock = get_index_stocks('000300.XSHG')
df_temp = get_price(all_stock,start_date='2005-4-1',end_date=date,fields=['close'])['close']
se_l = []
for i in date_list:
df_temp_1 = df_temp[df_temp.index<i]
#回撤
se = 1-df_temp_1[-1:]/df_temp_1.max()
#格式为series
se_l.append(se.T.quantile(0.5))
return pd.concat(se_l)
#次新股的破发率
#获取次新股和全市场股票的PE中位数
def f8(self,date_list):
sec_new_pe = []
pe = []
p_ratio_l = []
all_stock = get_all_securities(types='stock',date=date_list[-1])
all_stock['fir_open'] = [get_price(stock,end_date=all_stock.loc[stock]['start_date'],count=1,fields=['open'])['open'].values[0] for stock in all_stock.index]
for d in date_list:
df_temp = get_price('000001.XSHG',end_date=d,count=252)
year_1,month_1,day_1 = int(str(df_temp.index[0])[:4]), int(str(df_temp.index[0])[5:7]), int(str(df_temp.index[0])[8:10])
year,month,day = int(str(df_temp.index[-1])[:4]), int(str(df_temp.index[-1])[5:7]), int(str(df_temp.index[-1])[8:10])
sec_new_stock_df = all_stock[(all_stock['start_date']>datetime.date(year_1,month_1,day_1)) & (all_stock['start_date']<datetime.date(year,month,day))]
sec_new_stock = sec_new_stock_df.index
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(sec_new_stock)),date=d)
df_temp_1 = get_fundamentals(query(valuation.code,valuation.pe_ratio),date=d)
pe_sec = df_temp['pe_ratio'].quantile(0.5)
pe_all = df_temp_1['pe_ratio'].quantile(0.5)
sec_new_pe.append(pe_sec)
pe.append(pe_all)
#获取次新股当前价格
sec_new_price = get_price(list(sec_new_stock),end_date=d,fields=['close'],count=1)['close'].T
sec_new_price.columns=['fir_open']
p_ratio = sec_new_price['fir_open']/all_stock.loc[sec_new_price.index,:]['fir_open']
po_ratio = len(p_ratio[p_ratio<1])/len(p_ratio)
p_ratio_l.append(po_ratio)
df_pe = pd.DataFrame(sec_new_pe,index=date_list,columns=['sec_pe'])
df_pe['pe'] = pe
df_pe['p_ratio'] = p_ratio_l
return df_pe
#市场大底,行业一片惨淡,无一例外
#行业PE估值
def f9(self,date_list):
#指数用成分股,pe值做市值加权处理
index_list = ['000001.XSHG','000300.XSHG','000016.XSHG','000905.XSHG','000852.XSHG','399006.XSHE','399678.XSHE','399005.XSHE']
index_name = ['上证','沪深300','上证50','中证500','中证1000','创业板','次新股','中小板']
pe_fin = []
for i in date_list:
pe_index = []
for j in index_list:
stock_list = get_index_stocks(j,i)
df_temp = get_fundamentals(query(valuation.code,valuation.pe_ratio).filter(valuation.code.in_(stock_list)),date=i)
pe = df_temp['pe_ratio'].quantile(0.5)
pe_index.append(pe)
pe_fin.append(pe_index)
pe_df = pd.DataFrame(pe_fin,index=date_list,columns=index_name)
return pe_df
a = f()
date_list = a.get_tradeday_list('2005-7-17','2018-7-17')
df1 = a.f1(date_list)
df1.plot(figsize=(10,7))

df2 = a.f2(date_list)
df2.plot(figsize=(10,7))

df3 = a.f3(date_list)
#df3.plot(figsize=(10,7))
df3['market_50'] = df3['market_50%']*10**3
df3[['market_50','M2/总市值中位数']].plot(figsize=(10,7))

df4 = a.f4_1(date_list)
df4.plot(figsize=(10,7))

df4[['pe_50%','1/returns']].plot(figsize=(10,7))

df7 = a.f7(date_list)
df7.plot(figsize=(10,7))










