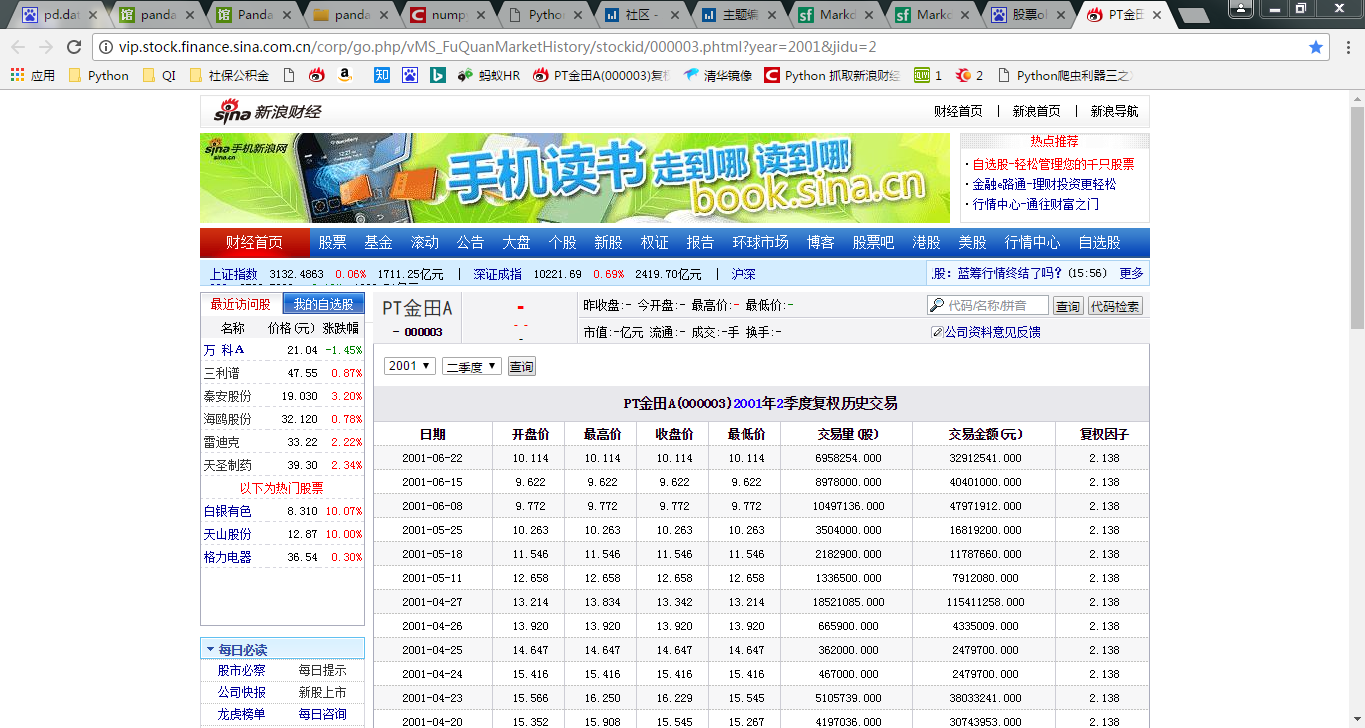
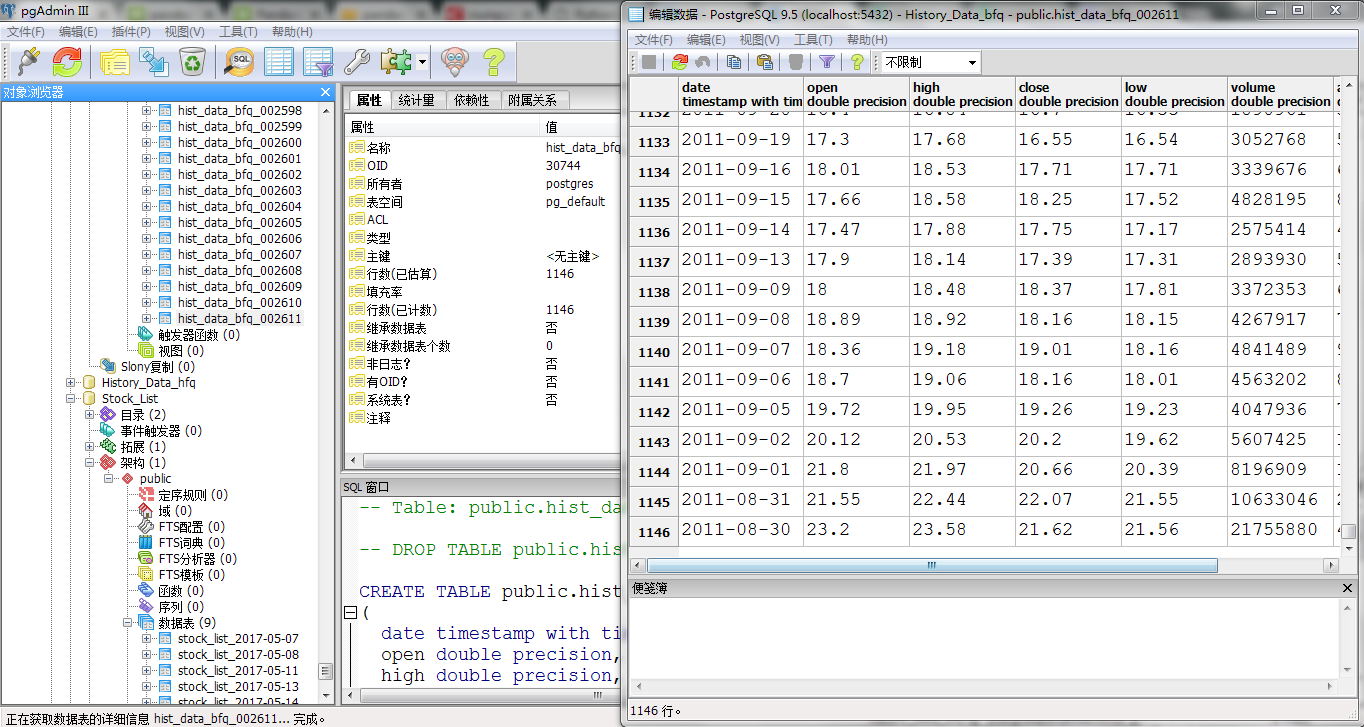
自己写的一些小代码,目标是从sina财经网页中批量抓取A股历史交易数据,并且在本地小型关系数据库中进行存储,方便随时调用。
主要两个内容:
1、确定最新的A股股票列表(包含上市和已经退市的所有股票);
2、获取所有个股自上市日起至今的日交易数据,并作“后复权”处理(包含date, open, high, low, close, volume, amount常规数据和后复权因子 factor)。
原始网页:
最终数据结果展示:
代码1:
# -*- coding: utf-8 -*-
"""
Created on Tue May 16 20:05:29 2017
@author: Jiang_Xin
"""
import sqlalchemy as sy
import pandas as pd
from sqlalchemy.orm import sessionmaker
import time
from datetime import date
import requests
import random
import socket
import http.client
from bs4 import BeautifulSoup
def get_content(url , data = None):
header={
'Accept':'text/html,application/xhtml xml,application/xml;q=0.9,\
image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/58.0.3029.96 Safari/537.36'
}
timeout = random.choice(range(6, 10))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'GBK'
break
except socket.timeout as e:
print( '3:', e)
time.sleep(random.choice(range(1,5)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(1, 5)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(1, 5)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(1, 5)))
return rep.text
def test_stock_code(html_text):
soup = BeautifulSoup(html_text, "lxml") # 创建BeautifulSoup对象
body = soup.body # 获取body部分
f_1 = body.find('div', {'id': 'toolbar'})
#找到有股票名称信息的栏位,即id为‘toolbar’的div
stock_name=f_1.find('h1').text
f_1_2=f_1.find('h2').text
if len(f_1_2)!=8:
return None
stock_code=f_1_2[-6:]
return pd.DataFrame({'code':[stock_code],'name':[stock_name]})
#读取并返回股票的名称和代码
def read_init_code(path):
return pd.read_excel(path,converters={0: str})
if __name__ == '__main__':
init_code=read_init_code('init_stock_list.xlsx')['code']
code_list=pd.DataFrame(columns=['code','name'])
for code in init_code:
print('\n',list(init_code).index(code),':开始测试',code,'....')
url='http://vip.stock.finance.sina.com.cn/' \
'corp/go.php/vMS_FuQuanMarketHistory/stockid/' \
code '.phtml?year=2017&jidu=1'
html = get_content(url)
temp = test_stock_code(html)
if temp is None:
print('×')
continue
code_list=code_list.append(temp,ignore_index=True)
print('√')
temp=[]
#连接至postgresql数据库
engine_1=sy.create_engine('postgresql://postgres:314159@127.0.0.1/Stock_List')
Session = sessionmaker(bind=engine_1) # 相当于 cursor
session = Session()
code_list.to_sql('stock_list_' str(date.today()),\
engine_1,\
if_exists='replace')
print('股票列表已全部生成(含已退市股票)!')
#提交确认数据/关闭游标/关闭连接
session.commit()
session.close()
代码2:
# -*- coding: utf-8 -*-
"""
Created on Wed Jun 14 15:13:43 2017
@author: Jiang_Xin
"""
import os
import numpy as np
import sqlalchemy as sy
import pandas as pd
import time
import requests
import random
import socket
import http.client
import bs4
from bs4 import BeautifulSoup
from sqlalchemy.orm import sessionmaker
from datetime import date
#获取网页html字符信息
def get_content(url , data = None):
header={
'Accept':'text/html,application/xhtml xml,application/xml;q=0.9,\
image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/58.0.3029.96 Safari/537.36'
}
timeout = random.choice(range(1, 3))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'GBK'
break
except socket.timeout as e:
print( '3:', e)
time.sleep(random.choice(range(1, 3)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(1, 3)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(1, 3)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(1, 3)))
return rep.text
#抓取本页特定代码股票对应年份季度的数据,以二维数组形式输出(无标题)
def get_stock_data(html_text):
soup = BeautifulSoup(html_text, "lxml") # 创建BeautifulSoup对象
body = soup.body # 获取body部分
tables=body.find('table', {'id':'FundHoldSharesTable'})
temp=[]
for row in tables.contents[5:]:
if type(row)==bs4.element.NavigableString:
continue
temp =(list(row.stripped_strings))
return np.reshape(np.array(temp),(-1,8))
#主程序
if __name__ == '__main__':
#连接至postgresql数据库
engine_1=sy.create_engine('postgresql://postgres:314159@127.0.0.1/Stock_List')
engine_2=sy.create_engine('postgresql://postgres:314159@127.0.0.1/History_Data_hfq')
Session = sessionmaker(bind=engine_2) # 相当于 cursor
session = Session()
#临时读取数据库中已存的最新的股票列表数据
stock_list_temp=pd.read_sql_table('stock_list_' str(date.today()),engine_1)
code_list_temp=stock_list_temp.code.sort_values()
code_list_temp.index=range(0,code_list_temp.size)
#根据数据库中已有的股票列表,在tushare中以3年为长度,分批抓取各股票的日数据
#k=0
columns=['open',\
'high',\
'close',\
'low',\
'volume',\
'amount',\
'factor']
code_data=np.empty([0,8])
for code in code_list_temp:
print('\n开始抓取',code,'.. ..index',list(code_list_temp).index(code))
time.sleep(1)
for y in np.arange(date.today().year,1989,-1):
print(y,'年数据...')
for season in [4,3,2,1]:
# 确定url
url='http://vip.stock.finance.sina.com.cn/' \
'corp/go.php/vMS_FuQuanMarketHistory/stockid/' code '.phtml?year=' \
str(y) '&jidu=' str(season)
s=1
t=0
while s:
try:
#调用子程序,获取对应网页的html字符信息
html_text=get_content(url , data = None)
s=0
except:
t =1
if t>3:
while 1:
status = os.system('ping www.baidu.com')
if status==1:
print('网络掉线!正在重连...')
os.system('netsh wlan connect name=Ziroom-17A')
time.sleep(10)
else:
print('网络连接恢复正常!')
break
print('5秒后即将进行第',t,'次请求...')
time.sleep(5)
#根据抓到的html信息定位至股票数据
data=get_stock_data(html_text)
#各年分季度数据叠加整合
code_data=np.vstack((code_data,data))
#完成个股数据抓取,做成DataFrame
dates=code_data[:,0]
df=pd.DataFrame(code_data[:,1:],index=dates,columns=columns)
#将DataFrmae存入数据库
df.to_sql('hist_data_hfq_' code,\
engine_2,\
if_exists='replace')
code_data=np.empty([0,8])
print(code,'已完成!')
#提交确认数据/关闭游标/关闭连接
session.commit()
session.close()

本社区仅针对特定人员开放
查看需注册登录并通过风险意识测评
5秒后跳转登录页面...
移动端课程